0
This week, we announced that Red Hat has been named a leader in The Forrester Wave™ Infrastructure Automation, Q1 2023. In an effort to help explain this result from our point of view, the following blog answers some of the most frequently asked questions.
What is The Forrester Wave?
“The Forrester Wave™ is a guide for buyers considering their purchasing options in a technology marketplace and is based on our analysis and opinion. To offer an equitable process for all participants, Forrester follows a publicly available methodology, which we apply consistently across all participating vendors.” [source]
Forrester has been a mainstay throughout people’s automation journeys, and Red Hat is proud to be recognized as a leader in the results of this Q1 2023 report.
What were the results?
Red Hat, specifically focused on Ansible Automation Platform, has been named a leader in the Q1, 2023 Forrester Wave™ Infrastructure Automation report.
Refer to the following graphic, that can be viewed in the final report:
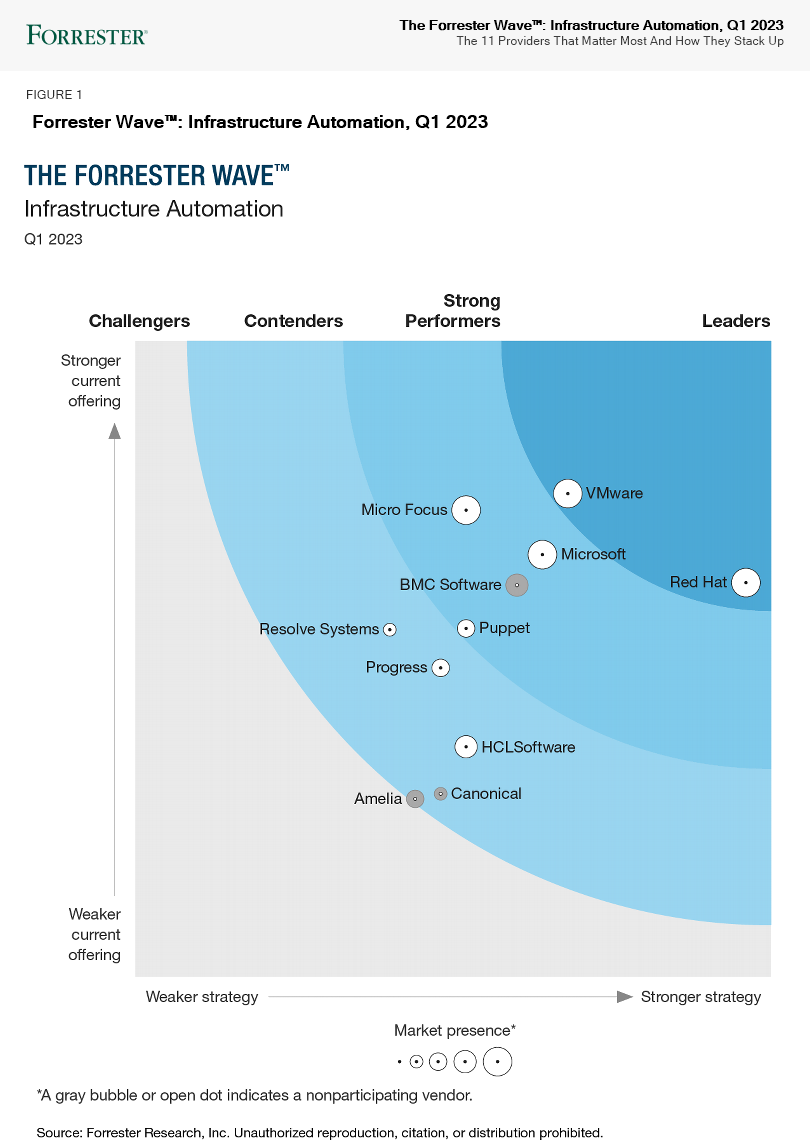
Why is this significant to us?
We believe Forrester is one of the most recognized technology analyst firms in the IT space, and Continue reading