Packet Actions – Python and Scapy
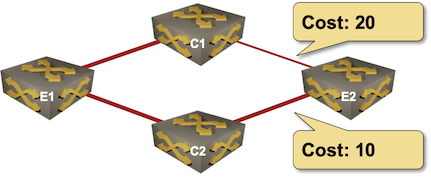
Hello and welcome to the “Packet Actions” series of blog posts. I’d like to spend a few posts talking through how you can programmatically integrate with a network dataplane. I had thrown around the idea of calling this series “Doing things with packets” but that seemed a bit long and also could mean just about anything. So what does Packet Actions mean? Well – its the shortest way I could come up with to say “Looking at packets on the wire and doing things based on what you see in the packet”. To discuss this further I’d like to talk about the often made analogy of network engineers being plumbers – an analogy that makes fairly good sense in most cases. For instance, network engineers create the paths for data to flow – plumbers make paths for water to flow. Additionally both need to make sure that there are no blockages or issues with handling the amount of data or water that needs to flow through the pipes. Going a step further – plumbers might use a diagnostic tool like a scope to physically look inside the pipes if theres a blockage or issue so they can see what’s going Continue reading