Introducing Workers Observability: logs, metrics, and queries – all in one place
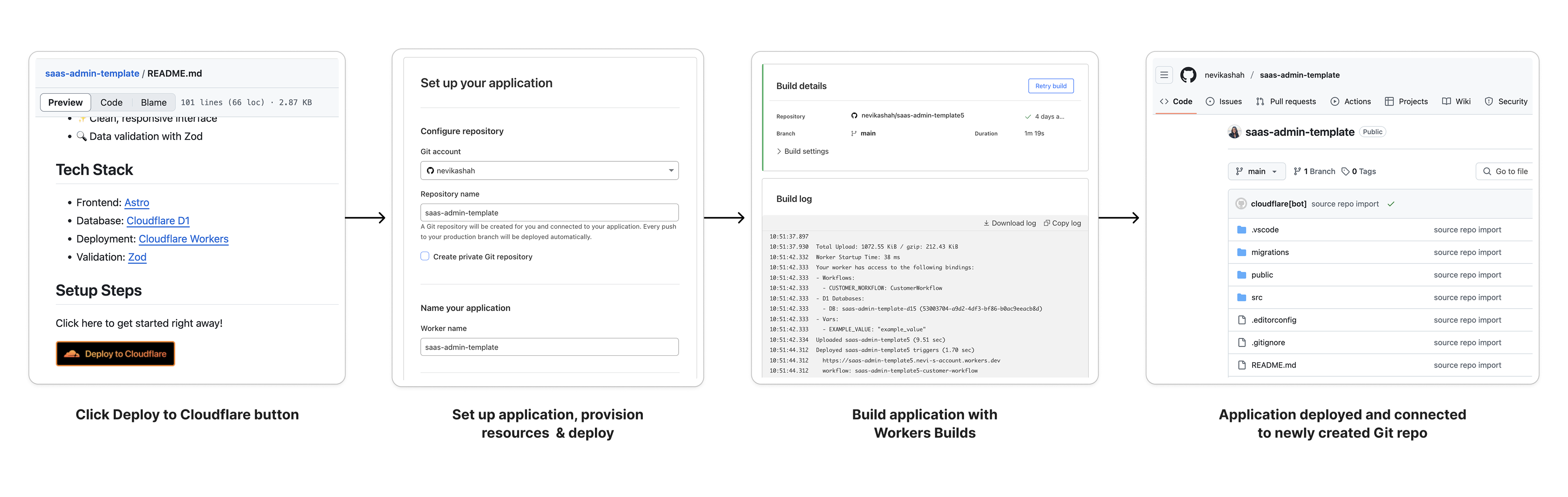
We’re excited to announce Workers Observability – a new section in the Cloudflare Dashboard that allows you to query detailed log events across all Workers in your account to extract deeper insights.
In 2024, we set out to build the best first-party observability for any cloud platform. Since then, we’ve improved metrics reporting for all resources, launched Workers Logs to automatically ingest and store logs for Workers, and rebuilt real-time logs with improved filtering. However, observability insights have been limited to a single Worker.
Starting today, you can use Workers Observability to understand what is happening across all of your Workers:
Workers Metrics Dashboard (Beta): A single dashboard to view metrics and logs from all of your Workers
Query Builder (Beta): Construct structured queries to explore your logs, extract metrics from logs, create graphical and tabular visualizations, and save queries for faster future investigations.
Workers Logs: Now Generally Available, with a public API and improved invocation-based grouping.
The Query Builder allows you to interact with your logs, and answer the “why” to any question you have. You can find it by navigating to Workers & Pages > Observability in the dashboard.
Using the Query Builder, you Continue reading