Tech Bytes: Performance, Power Efficiency Drive Dutch IXP Upgrade to Nokia Routers, Silicon (Sponsored)
Today on the Tech Bytes podcast, sponsored by Nokia, we hear from Nokia customer NL-IX. NL-IX is a leading Internet Exchange based in the Netherlands. The organization recently redesigned and upgraded its network. Nokia played a role in that upgrade, including 400 and 800G routers and FP5 silicon. We’re joined by Dirk Kalkman, Chief Network... Read more »Helping keep customers safe with leaked password notification
Password reuse is a real problem. When people use the same password across multiple services, it creates a risk that a breach of one service will give attackers access to a different, apparently unrelated, service. Attackers know people reuse passwords and build giant lists of known passwords and known usernames or email addresses.
If you got to the end of that paragraph and realized you’ve reused the same password multiple places, stop reading and go change those passwords. We’ll wait.
To help protect Cloudflare customers who have used a password attackers know about, we are releasing a feature to improve the security of the Cloudflare dashboard for all our customers by automatically checking whether their Cloudflare user password has appeared in an attacker's list. Cloudflare will securely check a customer’s password against threat intelligence sources that monitor data breaches in other services.
If a customer logs in to Cloudflare with a password that was leaked in a breach elsewhere on the Internet, Cloudflare will alert them and ask them to choose a new password.
For some customers, the news that their password was known to hackers will come as a surprise – no one wants to intentionally use passwords that Continue reading
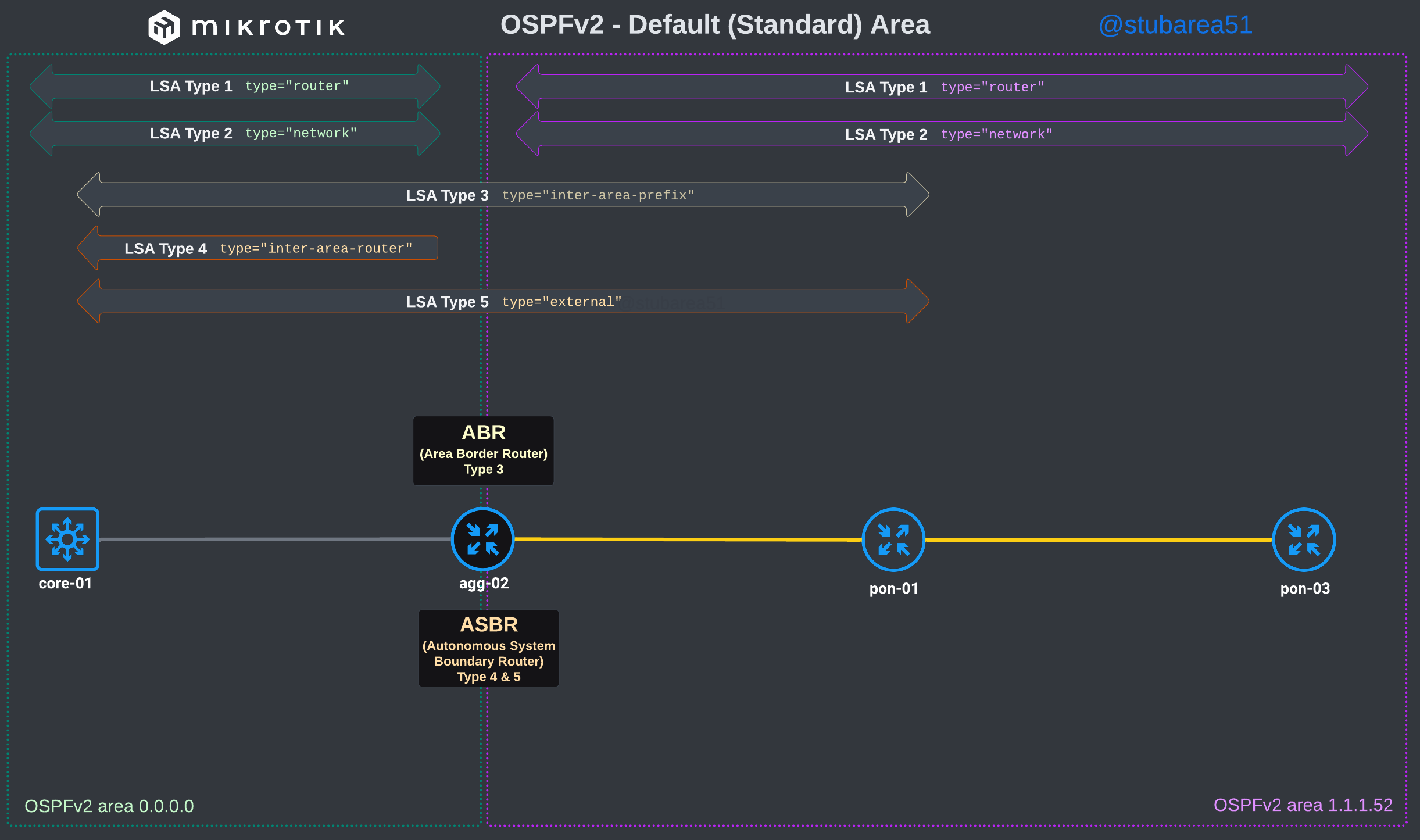
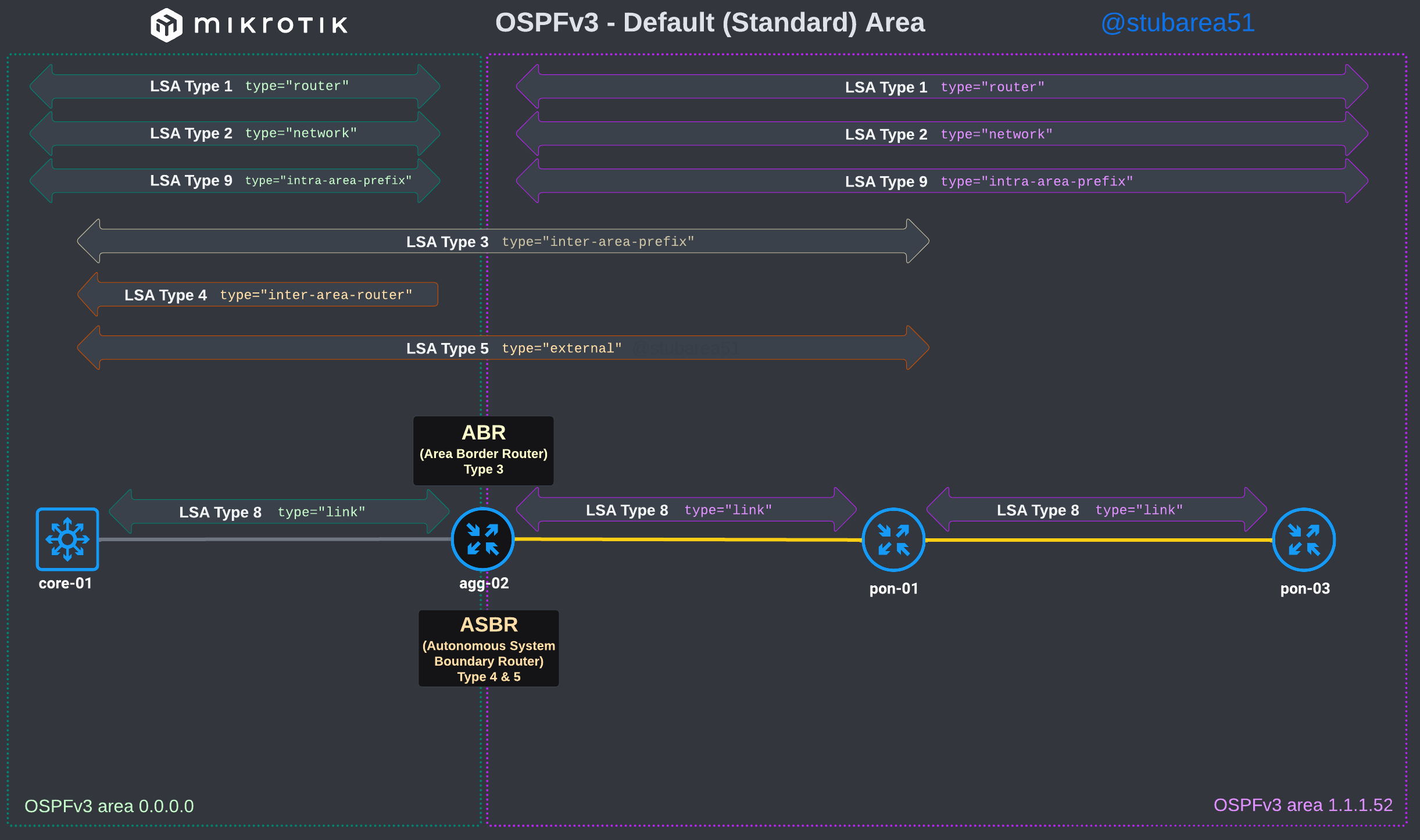
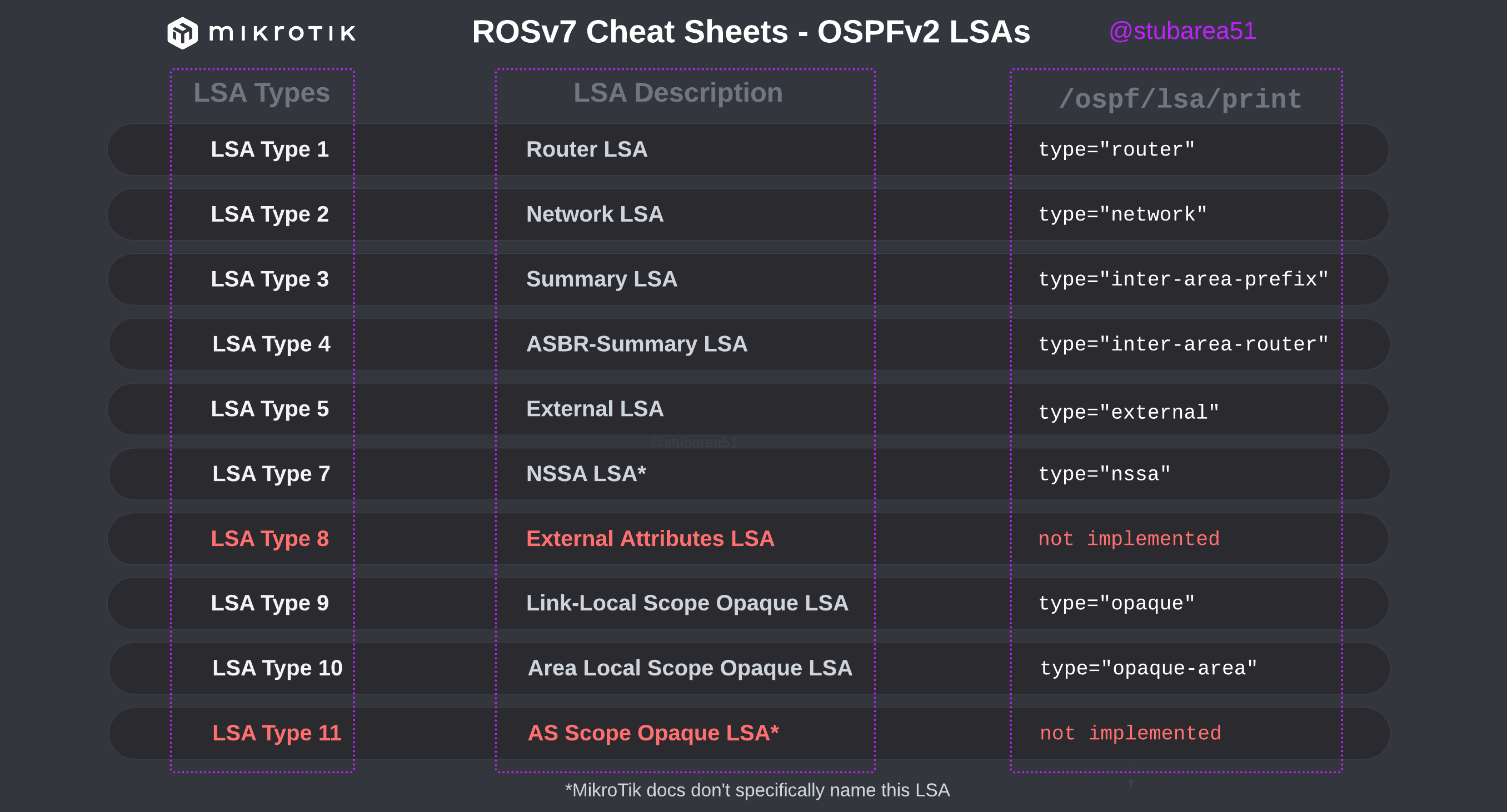
MikroTik ROSv7 Cheat Sheets – OSPFv2/v3 standard area LSA propagation.
When learning how to use OSPF with MikroTik, it can sometimes be difficult to understand how the different LSA types flow between areas.
In MikroTik’s OSPF documentation they briefly cover the LSA for OSPFv2 but don’t have OSPFv3 listed yet.
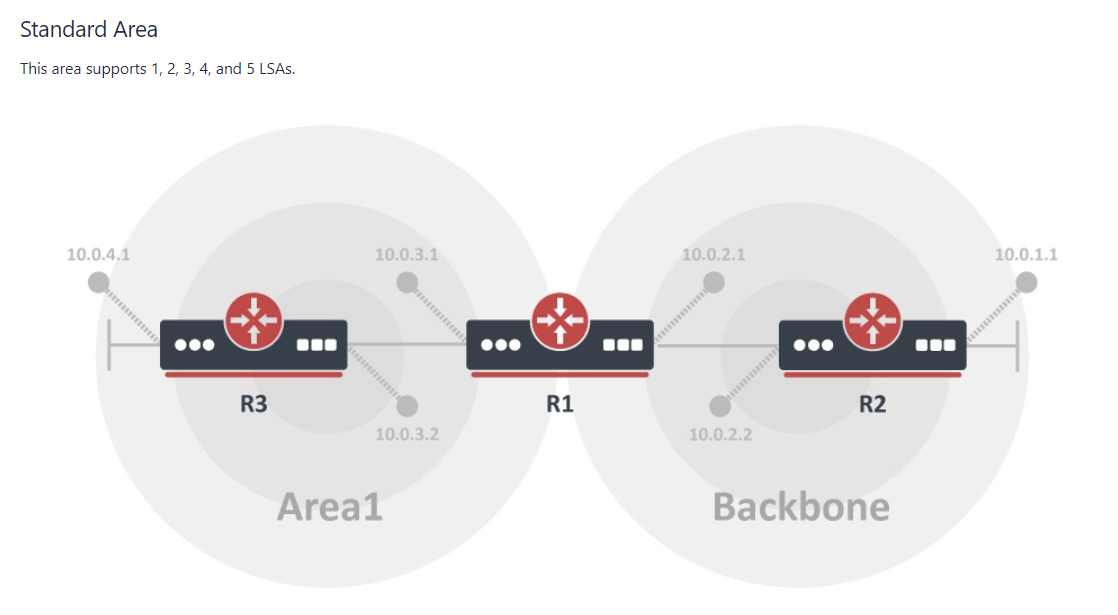
To better illustrate how the LSAs work, I created these graphical overviews for OSPFv2 and OSPFv3. When troubleshooting OSPF, it’s very helpful to understand which LSAs you should see in an area and how IPv4 and IPv6 differ.
Hope you find these helpful!
OSPFv2
OSPFv3
Using machine learning to detect bot attacks that leverage residential proxies
Bots using residential proxies are a major source of frustration for security engineers trying to fight online abuse. These engineers often see a similar pattern of abuse when well-funded, modern botnets target their applications. Advanced bots bypass country blocks, ASN blocks, and rate-limiting. Every time, the bot operator moves to a new IP address space until they blend in perfectly with the “good” traffic, mimicking real users’ behavior and request patterns. Our new Bot Management machine learning model (v8) identifies residential proxy abuse without resorting to IP blocking, which can cause false positives for legitimate users.
Background
One of the main sources of Cloudflare’s bot score is our bot detection machine learning model which analyzes, on average, over 46 million HTTP requests per second in real time. Since our first Bot Management ML model was released in 2019, we have continuously evolved and improved the model. Nowadays, our models leverage features based on request fingerprints, behavioral signals, and global statistics and trends that we see across our network.
Each iteration of the model focuses on certain areas of improvement. This process starts with a rigorous R&D phase to identify the emerging patterns of bot attacks by reviewing feedback from Continue reading
netlab 1.8.4: vrnetlab Containers, Catalyst 8000v
I don’t think I ever created two netlab releases in a week, but last week, I stumbled upon a motherlode of goodies, and it would be a shame not to make them available.
Someone tried to use netlab with vrnetlab containers for CSR 1000v and Nexus 9300v. We got it to work, but when I started integrating his changes into the development branch, I wanted to test them, so I installed vrnetlab to create my own container images. vrnetlab is an excellent tool, and building containers is a breeze (running them is a different story), so I added support for vrnetlab containers for every device supported by that tool and netlab for which I happened to have a disk image.
netlab 1.8.4: vrnetlab Containers, Catalyst 8000v
I don’t think I ever created two netlab releases in a week, but last week, I stumbled upon a motherlode of goodies, and it would be a shame not to make them available.
Someone tried to use netlab with vrnetlab containers for CSR 1000v and Nexus 9300v. We got it to work, but when I started integrating his changes into the development branch, I wanted to test them, so I installed vrnetlab to create my own container images. vrnetlab is an excellent tool, and building containers is a breeze (running them is a different story), so I added support for vrnetlab containers for every device supported by that tool and netlab for which I happened to have a disk image.
Why content providers need IPv6
IPv4 is an expensive resource. However, many content providers are still IPv4-only. The most common reason is that IPv4 is here to stay and IPv6 is an additional complexity.1 This mindset may seem selfish, but there are compelling reasons for a content provider to enable IPv6, even when they have enough IPv4 addresses available for their needs.
Disclaimer
It’s been a while since this article has been in my drafts. I started it when I was working at Shadow, a content provider, while I now work for Free, an internet service provider.
Why ISPs need IPv6?
Providing a public IPv4 address to each customer is quite costly when each IP address costs US$40 on the market. For fixed access, some consumer ISPs are still providing one IPv4 address per customer.2 Other ISPs provide, by default, an IPv4 address shared among several customers. For mobile access, most ISPs distribute a shared IPv4 address.
There are several methods to share an IPv4 address:3
- NAT44
- The customer device is given a private IPv4 address, which is translated to a public one by a service provider device. This device needs to maintain a state for each translation.
- 464XLAT Continue reading
Is your TLS resuming?
There are two main ways that a TLS handshake can go: Full handshake, or resume.
There are two benefits to resumption:
- it can save a round trip between the client and server.
- it saves CPU cost of a public key operation.
Round trip
Saving a round trip is important for latency. Some websites don’t use a CDN, so a roundtrip could take a while. And even those on a CDN can be tens of milliseconds away. Maybe won’t matter much for a human, but roundtrips can kill the performance of something that needs to do sequential connections.
E.g. Australia is far away:
$ ping -c 1 -n www.treasury.gov.au
PING treasury.gov.au (3.104.80.4) 56(84) bytes of data.
64 bytes from 3.104.80.4: icmp_seq=1 ttl=39 time=369 ms
That’s about a third of a second. Certainly noticeable to a human. Especially since rendering a web page usually requires many connections to different hosts.
For TCP based web requests (in other words: not QUIC), there’s usually four roundtrips involved (slightly simplified):
- TCP connection establishment.
- ClientHello & ServerHello.
- Client & Server ChangeCipherSpec.
- HTTP request & response.
So from the UK to Australia, that’s about Continue reading
Arista Network Test Automation (ANTA) Example

When I was at Autocon1, I visited the Arista booth and had an interesting chat with their team. They mentioned a tool called Arista Network Test Automation (ANTA), which sounded promising, and I wanted to try it out in my lab. As with anything related to automation, I always want to experiment and share my findings with my readers.
What is ANTA?
In a nutshell, if you work with Arista devices, you can use the ANTA Python library to write tests using a simple YAML declarative syntax. From a very high level, you define some tests, run them, and they either pass or fail. This straightforward approach helps you quickly verify the health and configuration of your network.
Here are some of the tests you can write.
- Checking if all your EOS devices are running a specific EOS version,
- Ensuring all BGP peers are up and running
- Verifying if you have a specific route on all or specific devices
- Verify PortChannels and Interfaces
- And many more
Here is a very simple test that checks if all my routers (6 in total) have the specified two routes in their routing tables. The test will fail if the route doesn't Continue reading
VPP with loopback-only OSPFv3 – Part 2
![]()
Introduction
When I first built IPng Networks AS8298, I decided to use OSPF as an IPv4 and IPv6 internal gateway protocol. Back in March I took a look at two slightly different ways of doing this for IPng, notably against a backdrop of conserving IPv4 addresses. As the network grows, the little point to point transit networks between routers really start adding up.
I explored two potential solutions to this problem:
- [Babel] can use IPv6 nexthops for IPv4 destinations - which is super useful because it would allow me to retire all of the IPv4 /31 point to point networks between my routers.
- [OSPFv3] makes it difficult to use IPv6 nexthops for IPv4 destinations, but in a discussion with the Bird Users mailinglist, we found a way: by reusing a single IPv4 loopback address on adjacent interfaces

In May I ran a modest set of two canaries, one between the two routers in my house (chbtl0 and
chbtl1), and another between a router at the Daedalean colocation and Interxion datacenters (ddln0
and chgtg0). AS8298 has about quarter of a /24 tied up in these otherwise pointless point-to-point
transit networks (see what Continue reading
Oracle OCI DRCC – Who, What, How? Regional Subnet – Happiness
Disclaimer: All writings and opinions are my own and are interpreted solely from my understanding. Please contact the concerned support teams for a professional opinion, as technology and features change rapidly.
Topics Discussed: DRCCs Intro and OCI Cloud Regional Subnet
Spoiler alert: This involves an on-premises cloud for customers offered by Oracle. All offerings for cloud@customer by Oracle can be viewed at https://www.oracle.com/cloud/cloud-at-customer/
Dedicate Region Cloud @Customer – DRCC

Ref: https://www.oracle.com/cloud/cloud-at-customer/dedicated-region/#rc30category-documentation
Before understanding DRCC, let’s consider the scope of improvement on customer premises with their own Data Center and what it tries to solve. Fair? Let’s imagine I have my own data centre. Great! My infrastructure supports some of my workloads, but how do I get the latest technology stack, support, and services that the public cloud offers?
For example, how can someone leverage all these services without having to invest in development cycles yet meet latency/integration/data security and multiple other requirements?

Ref: https://www.oracle.com/cloud/
| Scope of improvement on customer premises | Oracle Dedicated Region Cloud at Customer Solutions |
| Data Security and Compliance Concerns | Provides a fully managed cloud region in the customer’s datacenter, ensuring data sovereignty and compliance with local regulations. |
| Latency Continue reading |
Can Marvell Profit As It Tries To Triple Its Business By 2028?
A rising tide may lift all boats, and that is a good thing these days with any company that has an AI oar in the water. …
Can Marvell Profit As It Tries To Triple Its Business By 2028? was written by Timothy Prickett Morgan at The Next Platform.
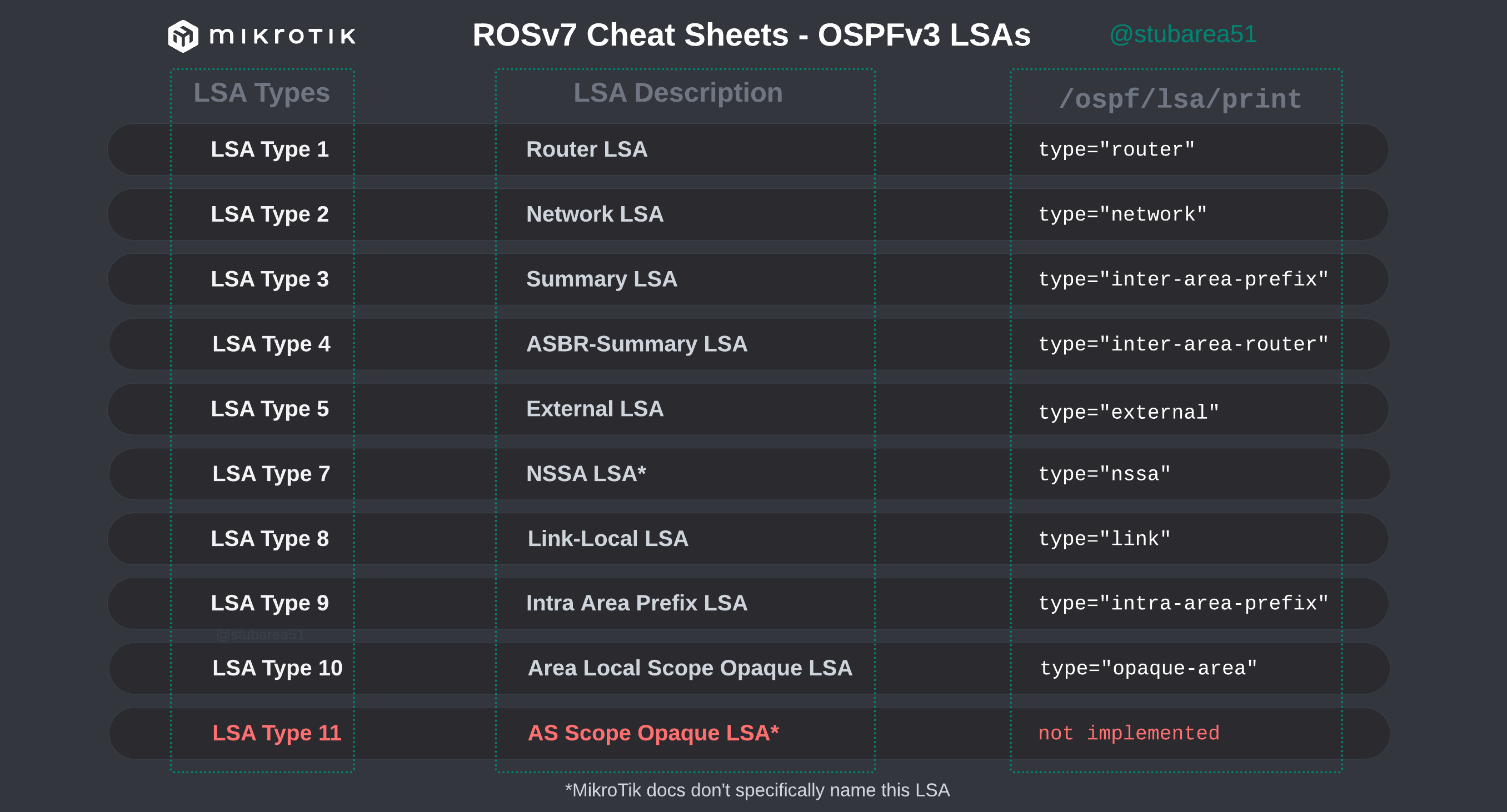
MikroTik ROSv7 cheat sheets – OSPFv2/v3 LSAs
When troubleshooting OSPF in MikroTik, it’s often helpful to look at the LSAs to determine the root cause of an issue.
However, MikroTik’s LSA names don’t always match up to the language used in RFCs and other resources when trying to verify the behavior of an LSA is working as intended. This can make troubleshooting difficult.
These cheat sheets match up the lsa description for OSPFv2 and OSPFv3 in RouterOSv7 with the common LSA Type and number reference.
PDF links are listed below – hope you find this helpful!
OSPFv2
PDF: https://stubarea51.net/wp-content/uploads/2024/06/ROSv7-OSPF-Fundamentals-SA51-LSA-Types-OSPFv2.pdf
OSPFv3
How the UEFA Euro 2024 football games are impacting local Internet traffic

Football (“soccer” in the US) is considered the most popular sport in the world, with around 3.5 billion fans spread across the world. European football is central to its popularity. The UEFA Euro 2024 (the European Football Championship) started on June 14 and will run until July 14, 2024. But how much do these games impact Internet traffic in countries where national teams are playing? That’s what we aim to explore in this blog post. We found that, on average, traffic dropped 6% during games in European countries with national teams playing in the tournament.
Cloudflare has a global presence with data centers in over 320 cities, which helps provide a global view of what’s happening on the Internet. This is helpful for security, privacy, efficiency, and speed purposes, but also for observing Internet disruptions and traffic trends.
In the past, we’ve seen how Internet traffic and HTTP requests are impacted by events such as total solar eclipses, the Super Bowl, and elections. 2024 is the year of elections, and we’ve been sharing our observations in blog posts and our new 2024 Election Insights report on Cloudflare Radar.
However, football games are different from elections. Related trends Continue reading

Hedge 231: Decoupling for Security
We often think of decoupling, or modularization in network engineering speak, as a primary tool for scaling networks, but it also one of the best tools network engineers have to increase security. In this roundtable, Eyvonne, Tom, and Russ discuss an article by Bruce Schneier on decoupling, and how it applies to networking engineering.
download
HN739: High Stakes Network Observability for High Frequency Trading
High Frequency Trading in finance demands the utmost quality and speed from a network, making flawless observability a must. Our guest today is Radu Ionco from Jump Trading, and he tells us about how they built their own custom network observability platform, even creating a monitoring system for the monitoring system. We talk through streaming... Read more »Exam-ining recent Internet shutdowns in Syria, Iraq, and Algeria

The practice of cheating on exams (or at least attempting to) is presumably as old as the concept of exams itself, especially when the results of the exam can have significant consequences for one’s academic future or career. As access to the Internet became more ubiquitous with the growth of mobile connectivity, and communication easier with an assortment of social media and messaging apps, a new avenue for cheating on exams emerged, potentially facilitating the sharing of test materials or answers. Over the last decade, some governments have reacted to this perceived risk by taking aggressive action to prevent cheating, ranging from targeted DNS-based blocking/filtering to multi-hour nationwide shutdowns across multi-week exam periods.
Syria and Iraq are well-known practitioners of the latter approach, and we have covered past exam-related Internet shutdowns in Syria (2021, 2022, 2023) and Iraq (2022, 2023) here on the Cloudflare blog. It is now mid-June 2024, and exams in both countries took place over the last several weeks, and with those exams, regular nationwide Internet shutdowns. In addition, Baccalaureate exams also took place in Algeria, and we have written about related Internet disruptions there in the past ( Continue reading
Worth Reading: You Probably Don’t Need AI
Here’s another rant to spice up your weekend: focus on fixing your company’s problems instead of chanting the AI mantra. Have fun ;)
Worth Reading: You Probably Don’t Need AI
Here’s another rant to spice up your weekend: focus on fixing your company’s problems instead of chanting the AI mantra. Have fun ;)