Bringing authentication and identification to Workers through Mutual TLS


We’re excited to announce that Workers will soon be able to send outbound requests through a mutually authenticated channel via mutual TLS authentication!
When making outbound requests from a Worker, TLS is always used on the server side, so that the client can validate that the information is being sent to the right destination. But in the same way, the server may want to authenticate the client to ensure that the request is coming from an authorized client. This two-way street of authentication is called Mutual TLS. In this blog, we’re going to talk through the importance of mutual TLS authentication, what it means to use mutual TLS within Workers, and how in a few months you’ll be able to use it to send information through an authenticated channel — adding a layer of security to your application!
mTLS between Cloudflare and an Origin
Mutual TLS authentication works by having a server validate the client certificate against a CA. If the validation passes then the server knows that it’s the right client and will let the request go through. If the validation fails or if a client certificate is not presented then the server can choose to drop the request.
Xata Workers: client-side database access without client-side secrets


We’re excited to have Xata building their serverless functions product – Xata Workers – on top of Workers for Platforms. Xata Workers act as middleware to simplify database access and allow their developers to deploy functions that sit in front of their databases. Workers for Platforms opens up a whole suite of use cases for Xata developers all while providing the security, scalability and performance of Cloudflare Workers.
Now, handing it over to Alexis, a Senior Software Engineer at Xata to tell us more.
Introduction
In the last few years, there's been a rise of Jamstack, and new ways of thinking about the cloud that some people call serverless or edge computing. Instead of maintaining dedicated servers to run a single service, these architectures split applications in smaller services or functions.
By simplifying the state and context of our applications, we can benefit from external providers deploying these functions in dozens of servers across the globe. This architecture benefits the developer and user experience alike. Developers don’t have to manage servers, and users don’t have to experience latency. Your application simply scales, even if you receive hundreds of thousands of unexpected visitors.
When it comes to databases though, we still Continue reading
Automate an isolated browser instance with just a few lines of code
If you’ve ever created a website that shows any kind of analytics, you’ve probably also thought about adding a “Save Image” or “Save as PDF” button to store and share results. This isn’t as easy as it seems (I can attest to this firsthand) and it’s not long before you go down a rabbit hole of trying 10 different libraries, hoping one will work.
This is why we’re excited to announce a private beta of the Workers Browser Rendering API, improving the browser automation experience for developers. With browser automation, you can programmatically do anything that a user can do when interacting with a browser.
The Workers Browser Rendering API, or just Rendering API for short, is our out-of-the-box solution for simplifying developer workflows, including capturing images or screenshots, by running browser automation in Workers.
Browser automation, everywhere
As with many of the best Cloudflare products, Rendering API was born out of an internal need. Many of our teams were setting up or wanted to set up their own tools to perform what sounds like an incredibly simple task: taking automated screenshots.
When gathering use cases, we realized that much of what our internal teams wanted would also be useful Continue reading
Making static sites dynamic with Cloudflare D1

Introduction

There are many ways to store data in your applications. For example, in Cloudflare Workers applications, we have Workers KV for key-value storage and Durable Objects for real-time, coordinated storage without compromising on consistency. Outside the Cloudflare ecosystem, you can also plug in other tools like NoSQL and graph databases.
But sometimes, you want SQL. Indexes allow us to retrieve data quickly. Joins enable us to describe complex relationships between different tables. SQL declaratively describes how our application's data is validated, created, and performantly queried.
D1 was released today in open alpha, and to celebrate, I want to share my experience building apps with D1: specifically, how to get started, and why I’m excited about D1 joining the long list of tools you can use to build apps on Cloudflare.
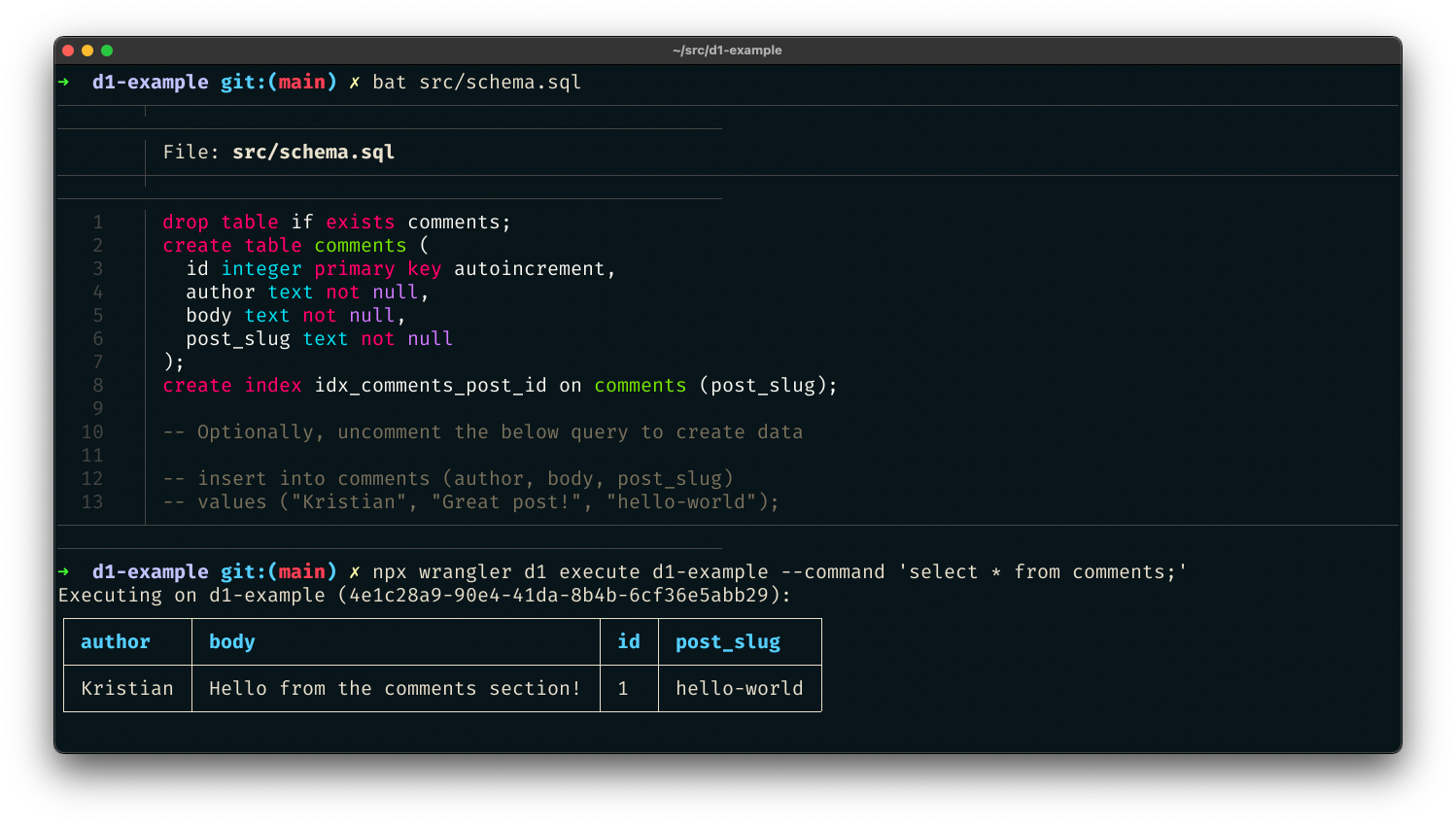
D1 is remarkable because it's an instant value-add to applications without needing new tools or stepping out of the Cloudflare ecosystem. Using wrangler, we can do local development on our Workers applications, and with the addition of D1 in wrangler, we can now develop proper stateful applications locally as well. Then, when it's time to deploy the application, wrangler allows us to both access and execute commands to Continue reading
Iteration isn’t just for code: here are our latest API docs
We’re excited to share that the next iteration of Cloudflare’s API reference documentation is now available. The new docs standardize our API content and improve the overall developer experience for interacting with Cloudflare’s API.
Why does API documentation matter?
Everyone talks about how important APIs are, but not everyone acknowledges the critical role that API documentation plays in an API’s usability. Throwing docs together is easy. Getting them right is harder.
At Cloudflare, we try to meet our users where they are. For the majority of customers, that means providing clear, easy-to-use products in our dashboard. But developers don’t always want what our dashboard provides. Some developers prefer to use a CLI or Wrangler to have a higher level of control over what’s happening with their Cloudflare products. Others want more customization and deeper ties into their company’s internal applications. Some want all the above.

A developer’s job is to create, debug, and optimize code - whether that’s an application, interface, database, etc. - as efficiently as possible and ensure that code runs as efficiently as possible. APIs enable that efficiency through automation. Let’s say a developer wants to run a cache purge every time content is updated on their Continue reading
The Cloudflare API now uses OpenAPI schemas


Today, we are announcing the general availability of OpenAPI Schemas for the Cloudflare API. These are published via GitHub and will be updated regularly as Cloudflare adds and updates APIs. OpenAPI is the widely adopted standard for defining APIs in a machine-readable format. OpenAPI Schemas allow for the ability to plug our API into a wide breadth of tooling to accelerate development for ourselves and customers. Internally, it will make it easier for us to maintain and update our APIs. Before getting into those benefits, let’s start with the basics.
What is OpenAPI?
Much of the Internet is built upon APIs (Application Programming Interfaces) or provides them as services to clients all around the world. This allows computers to talk to each other in a standardized fashion. OpenAPI is a widely adopted standard for how to define APIs. This allows other machines to reliably parse those definitions and use them in interesting ways. Cloudflare’s own API Shield product uses OpenAPI schemas to provide schema validation to ensure only well-formed API requests are sent to your origin.
Cloudflare itself has an API that customers can use to interface with our security and performance products from other places on the Internet. How Continue reading
How To Submit Your Ideas To The IETF
In this first blog in a new series, Russ White demystifies the IETF and the process of how ideas move through the process to a Request for Comment (RFC). He also discusses the IETF itself, its culture and it how works, and how anyone, including you, can submit an idea for comments and consideration.
The post How To Submit Your Ideas To The IETF appeared first on Packet Pushers.
BGP in ipSpace.net Design Clinic
The ipSpace.net Design Clinic has been running for a bit over than a year. We covered tons of interesting technologies and design challenges, resulting in over 13 hours of content (so far), including several BGP-related discussions:
- BGP route servers
- Redundant BGP-Based Internet Access
- Secure BGP Configuration on Customer Routers
- Enterprise WAN Routing Design
All the Design Clinic discussions are available with Standard or Expert ipSpace.net Subscription, and anyone can submit new design/discussion challenges.
BGP in ipSpace.net Design Clinic
The ipSpace.net Design Clinic has been running for a bit over than a year. We covered tons of interesting technologies and design challenges, resulting in over 13 hours of content (so far), including several BGP-related discussions:
- BGP route servers
- Redundant BGP-Based Internet Access
- Secure BGP Configuration on Customer Routers
- Enterprise WAN Routing Design
All the Design Clinic discussions are available with Standard or Expert ipSpace.net Subscription, and anyone can submit new design/discussion challenges.
3 Critical IT Elements Every CIO and IT Director Must Address for Success
With nearly every company now a digital business, IT systems no longer have to simply run. They suddenly are the livelihood of the company.Using the MITRE ATT&CK framework to understand container security
As innovations in the world of application development and data computation grow every year, the “attack surface” of these technologies grows as well. The attack surface has to be understood from two sides—from the attacker’s side and from the organization being attacked. For the attacker, they benefit from the entry point into a system, either through the ever-growing perimeter of public-facing applications or the people managing these applications, because the probability of finding a weakness to enter from these entry points is higher. For the organization, managing the attack surface requires investing in more security tools and personnel. This can cascade into bigger security issues, which is why addressing the attack surface is essential.
The MITRE adversarial tactics, techniques, and common knowledge (ATT&CK) framework can help us understand how this large attack surface can be exploited by an adversary and how they strategize an attack. In this two-part blog, I will cover the new ATT&CK matrix for containers and how Calico provides mitigation solutions for each tactic in the matrix. In this blog, we will explore the first four tactics, which mostly deal with reconnaissance. In the second part, we will discuss the techniques and mitigation strategies once an attacker Continue reading
DPUs And The Future Of Distributed Infrastructure: A Packet Pushers Livestream Event
If you want to understand Data Processing Units (DPUs) and how they might impact your work as a network or infrastructure professional, join the Packet Pushers and Dell Technologies for a sponsored Livestream event on December 13th. What’s A DPU? Is It Like A DUI? It’s definitely not a DUI. DPUs are dedicated hardware that […]
The post DPUs And The Future Of Distributed Infrastructure: A Packet Pushers Livestream Event appeared first on Packet Pushers.
Scientific network tags (scitags)

Scientific network tags (scitags) is an initiative promoting identification of the science domains and their high-level activities at the network level. Participants include, dCache, ESnet, GÉANT, Internet2, Jisc, NORDUnet, OFTS, OSG, RNP, RUCIO, StarLight, XRootD.

This article will demonstrate how industry standard sFlow telemetry streaming from switches and routers can be used to report on science domain activity in real-time using the sFlow-RT analytics engine.

The scitags initiative makes use of the IPv6 packet header to mark traffic. Experiment and activity identifiers are encoded in the IPv6 Flow label field. Identifiers are published in an online registry in the form of a JSON document, https://www.scitags.org/api.json.
One might expect IPFIX / NetFlow to be a Continue reading
Full Stack Journey 072: A Peek Inside The Comp Sci Ivory Tower
On today's Full Stack Journey podcast we climb the ivory tower to get a glimpse of academic life in the field of networking and computer science with guest Dave Levin. Dr. Levin is Assistant Professor of Computer Science at the University of Maryland. His research focuses on networking and security, including measurement, cryptography, artificial intelligence, and economics.
The post Full Stack Journey 072: A Peek Inside The Comp Sci Ivory Tower appeared first on Packet Pushers.
Full Stack Journey 072: A Peek Inside The Comp Sci Ivory Tower
On today's Full Stack Journey podcast we climb the ivory tower to get a glimpse of academic life in the field of networking and computer science with guest Dave Levin. Dr. Levin is Assistant Professor of Computer Science at the University of Maryland. His research focuses on networking and security, including measurement, cryptography, artificial intelligence, and economics.Migrate from S3 easily with the R2 Super Slurper
R2 is an S3-compatible, globally distributed object storage, allowing developers to store large amounts of unstructured data without the costly egress bandwidth fees you commonly find with other providers.
To enjoy this egress freedom, you’ll have to start planning to send all that data you have somewhere else into R2. You might want to do it all at once, moving as much data as quickly as possible while ensuring data consistency. Or do you prefer moving the data to R2 slowly and gradually shifting your reads from your old provider to R2? And only then decide whether to cut off your old storage or keep it as a backup for new objects in R2?
There are multiple options for architecture and implementations for this movement, but taking terabytes of data from one cloud storage provider to another is always problematic, always involves planning, and likely requires staffing.
And that was hard. But not anymore.
Today we're announcing the R2 Super Slurper, the feature that will enable you to move all your data to R2 in one giant slurp or sip by sip — all in a friendly, intuitive UI and API.

The first step: R2 Super Slurper Private Beta
One Continue reading
Get started with Cloudflare Workers with ready-made templates


One of the things we prioritize at Cloudflare is enabling developers to build their applications on our developer platform with ease. We’re excited to share a collection of ready-made templates that’ll help you start building your next application on Workers. We want developers to get started as quickly as possible, so that they can focus on building and innovating and avoid spending so much time configuring and setting up their projects.
Introducing Cloudflare Workers Templates
Cloudflare Workers enables you to build applications with exceptional performance, reliability, and scale. We are excited to share a collection of templates that helps you get started quickly and give you an idea of what is possible to build on our developer platform.
We have made available a set of starter templates highlighting different use cases of Workers. We understand that you have different ideas you will love to build on top of Workers and you may have questions or wonder if it is possible. These sets of templates go beyond the convention ‘Hello, World’ starter. They’ll help shape your idea of what kind of applications you can build with Workers as well as other products in the Cloudflare Developer Ecosystem.
We are excited to Continue reading