Tech Bytes: Misconceptions About Connecting Your Network To The Cloud (Sponsored)
This Day Two Cloud Tech Bytes episode, sponsored by Singtel, discusses common customer misconceptions about connecting private networks to the public cloud. For instance, SD-WAN might seem like a simple option, but things get tricky when you're talking about hundreds of sites across different countries. Our guest is Mark Seabrook, Global Solutions Manager at Singtel.
The post Tech Bytes: Misconceptions About Connecting Your Network To The Cloud (Sponsored) appeared first on Packet Pushers.
Tech Bytes: Misconceptions About Connecting Your Network To The Cloud (Sponsored)
This Day Two Cloud Tech Bytes episode, sponsored by Singtel, discusses common customer misconceptions about connecting private networks to the public cloud. For instance, SD-WAN might seem like a simple option, but things get tricky when you're talking about hundreds of sites across different countries. Our guest is Mark Seabrook, Global Solutions Manager at Singtel.Day Two Cloud 135: Infrastructure As Code Should Foster Infrastructure As Collaboration
On today's Day Two Cloud we examine why Infrastructure as Code (IaC) is about more than the just the tools that enable it. Guest Rob Hirschfeld puts forth the notion that while the tools are there for a reason, those tools have to serve a purpose: supporting collaboration, re-use, and efficient operations.Podcast Guest: Can You Have A Successful IT Career Without A Degree?
I was a guest on the February 22, 2022 episode of the So You Wanna Be In IT podcast.
Certifications
I chatted with hosts Pat & Dean about how my career got started. I’ve been around IT since the 90s, so my start was with Novell certification that became Microsoft certification that became Cisco certification. We talk about certs and the job opportunities I took advantage of driven by those certs.
Can You Have A Successful IT Career Without A Degree?
Along the way, we discussed whether or not someone can have a successful IT career without a college degree. Put another way, are IT certifications good enough? I think that yes, you can have a successful IT career without a degree, but that the question, “College degree. Yes or no?” deserves more analysis than a simple yes or no answer offers. Like anything, choosing not to attend university has tradeoffs. We discuss this at some length in the podcast.
What IT Roles Are In Demand In 2022?
The degree vs. certifications part of the discussion transitioned into my takes on IT careers in 2022–especially related to infrastructure. 2022 is an interesting time to be in IT. There are Continue reading
3G Sunsetting Reality Sets In as AT&T Turns Off Service
Businesses that did not replace 3G equipment due the impact of COVID, supply chain issues, and worker shortages saw the impact this week as 3G sunsetting began.Tech Bytes: Improve Network TCO, Enable Cloud-Like Innovation And More With DriveNets (Sponsored)
Today on the Tech Bytes podcast, we’re talking about how your organization can adopt a hyperscale model in your network to improve TCO, scale out capabilities and services, and get supply chain diversity. Our sponsor is DriveNets, and we’re speaking with Run Almog, Head of Product Strategy.
The post Tech Bytes: Improve Network TCO, Enable Cloud-Like Innovation And More With DriveNets (Sponsored) appeared first on Packet Pushers.
Tech Bytes: Improve Network TCO, Enable Cloud-Like Innovation And More With DriveNets (Sponsored)
Today on the Tech Bytes podcast, we’re talking about how your organization can adopt a hyperscale model in your network to improve TCO, scale out capabilities and services, and get supply chain diversity. Our sponsor is DriveNets, and we’re speaking with Run Almog, Head of Product Strategy.The Migration from Network Security to Secure Networks

Over the last few years, we have seen an age of edgeless, multi-cloud, multi-device collaboration for hybrid work giving rise to a new network that transcends traditional perimeters. As hybrid work models gain precedence through the new network, organizations must address the cascading attack surface. Reactionary, bolt-on security measures are simply too tactical and expensive.
Making protocols post-quantum
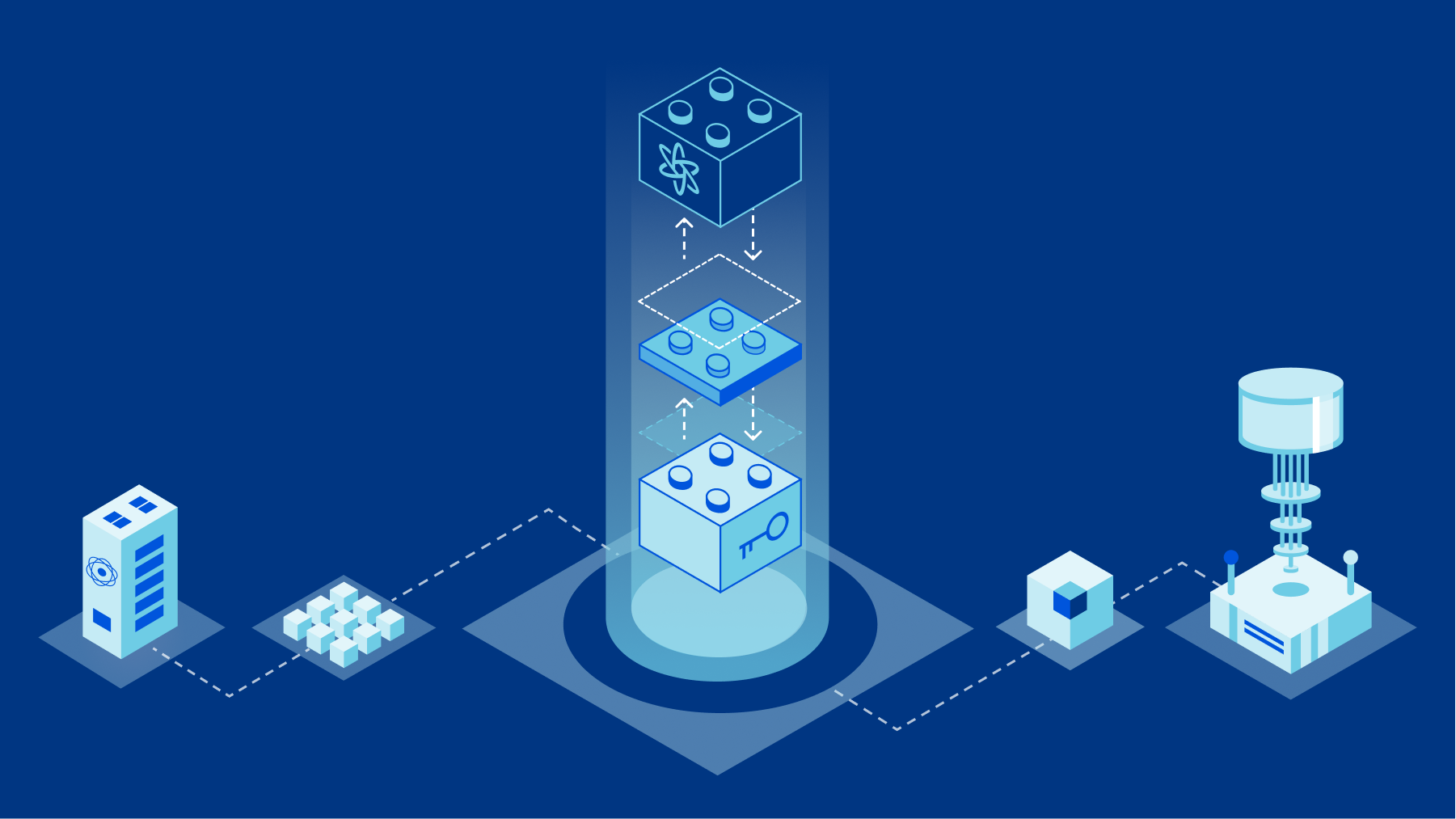
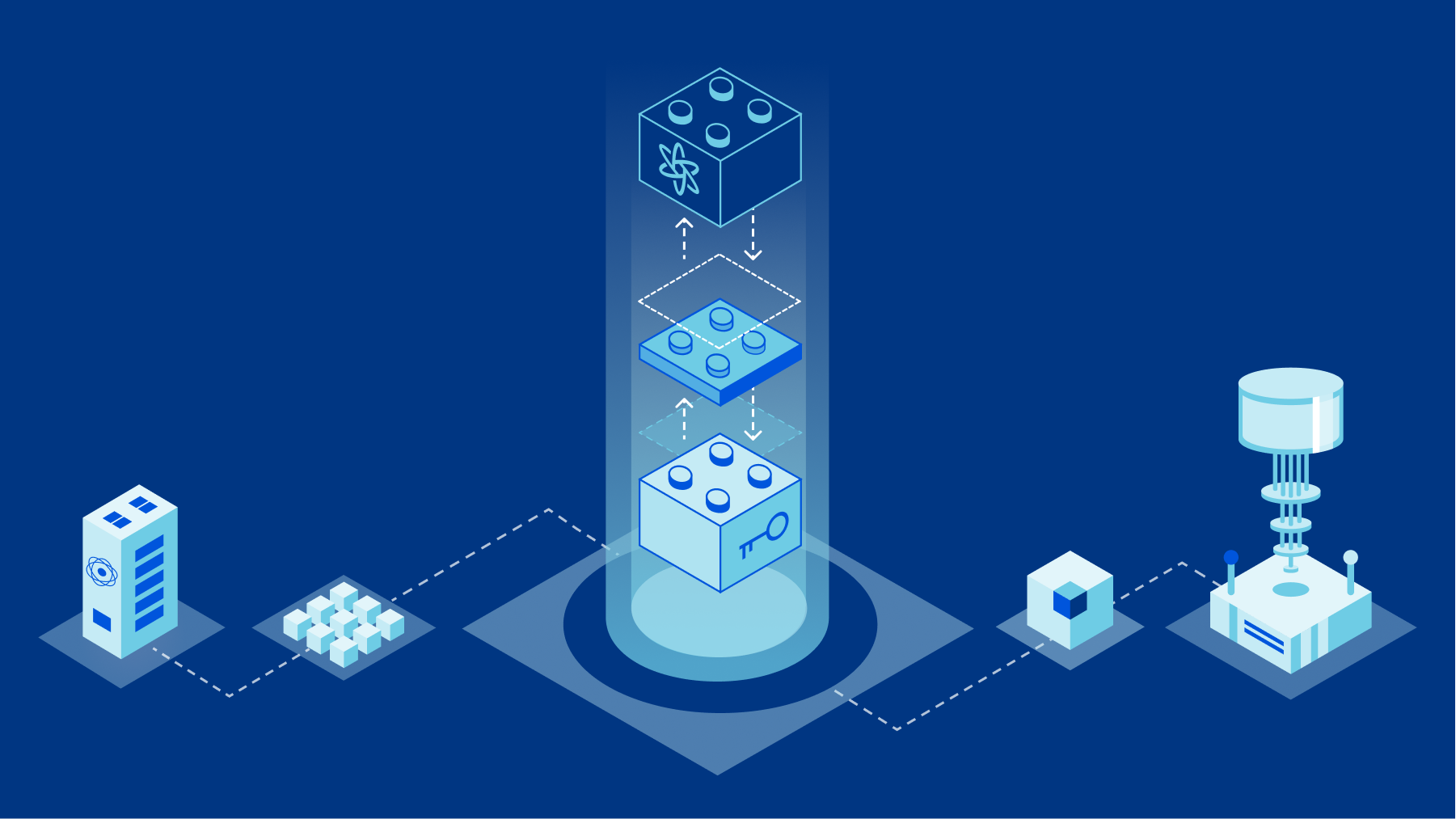
Ever since the (public) invention of cryptography based on mathematical trap-doors by Whitfield Diffie, Martin Hellman, and Ralph Merkle, the world has had key agreement and signature schemes based on discrete logarithms. Rivest, Shamir, and Adleman invented integer factorization-based signature and encryption schemes a few years later. The core idea, that has perhaps changed the world in ways that are hard to comprehend, is that of public key cryptography. We can give you a piece of information that is completely public (the public key), known to all our adversaries, and yet we can still securely communicate as long as we do not reveal our piece of extra information (the private key). With the private key, we can then efficiently solve mathematical problems that, without the secret information, would be practically unsolvable.
In later decades, there were advancements in our understanding of integer factorization that required us to bump up the key sizes for finite-field based schemes. The cryptographic community largely solved that problem by figuring out how to base the same schemes on elliptic curves. The world has since then grown accustomed to having algorithms where public keys, secret keys, and signatures are just a handful of Continue reading
BGP security and confirmation biases


This is not what I imagined my first blog article would look like, but here we go.
On February 1, 2022, a configuration error on one of our routers caused a route leak of up to 2,000 Internet prefixes to one of our Internet transit providers. This leak lasted for 32 seconds and at a later time 7 seconds. We did not see any traffic spikes or drops in our network and did not see any customer impact because of this error, but this may have caused an impact to external parties, and we are sorry for the mistake.
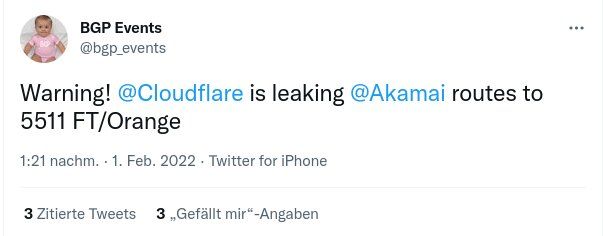
Timeline
All timestamps are UTC.
As part of our efforts to build the best network, we regularly update our Internet transit and peering links throughout our network. On February 1, 2022, we had a “hot-cut” scheduled with one of our Internet transit providers to simultaneously update router configurations on Cloudflare and ISP routers to migrate one of our existing Internet transit links in Newark to a link with more capacity. Doing a “hot-cut” means that both parties will change cabling and configuration at the same time, usually while being on a conference call, to reduce downtime and impact on the network. Continue reading
Evolution of Transistor Innovation – Intel
New netsim-tools Installation Instructions
A long-time subscriber with a knack for telling me precisely why something I’m doing sucks big time sent me his opinion on netsim-tools installation instructions:
I do not want to say it is impossible to follow your instruction but I wonder why the process is not clearly defined for someone not deeply involved in such tasks with full understanding of why to install from github, etc..
Many guys do not know if they want to use libvirt. They want to use the tool simple way without studying upfront what the libvirt is - but they see libvirt WARNING - should we install libvirt then or skip the installation?. But stop, this step of libvirt installation is obligatory in the 2nd Ubuntu section. So why the libvirt warning earlier?
I believe we should start really quickly to enjoy the tool before we reject it for “complexity”. Time To Play matters. Otherwise you are tired trying to understand the process before you check if this tool is right for you.
He was absolutely right – it was time to overhaul the “organically grown” installation instructions and make them goal-focused and structured. For those of you who want to see the big picture Continue reading
New netlab Installation Instructions
A long-time subscriber with a knack for telling me precisely why something I’m doing sucks big time sent me his opinion on netlab1 installation instructions:
I do not want to say it is impossible to follow your instruction but I wonder why the process is not clearly defined for someone not deeply involved in such tasks with full understanding of why to install from github, etc..
Many guys do not know if they want to use libvirt. They want to use the tool simple way without studying upfront what the libvirt is - but they see libvirt WARNING - should we install libvirt then or skip the installation?. But stop, this step of libvirt installation is obligatory in the 2nd Ubuntu section. So why the libvirt warning earlier?
I believe we should start really quickly to enjoy the tool before we reject it for “complexity”. Time To Play matters. Otherwise you are tired trying to understand the process before you check if this tool is right for you.
He was absolutely right – it was time to overhaul the “organically grown” installation instructions and make them goal-focused and structured. For those of you who want to see the big Continue reading
Rust Load a TOML File
Good Morro Crusty ones 😘. In todays episode of learning Rust, I will show you how to load a TOML file in Rust and additionally handle any possible errors. Software The following software was used in this post. Rust - 1.57.0 toml crate - 0.5.2 serde crate - 1.0.136 ...continue reading