Enterprise Wi-Fi 6E Investments: Timing Is Everything
While today may not be the right time for enterprises to fully transition to Wi-Fi 6E, now IS the right time to prepare for the shift and ensure that they aren’t left behind.Incorrect proxying of 24 hostnames on January 24, 2022
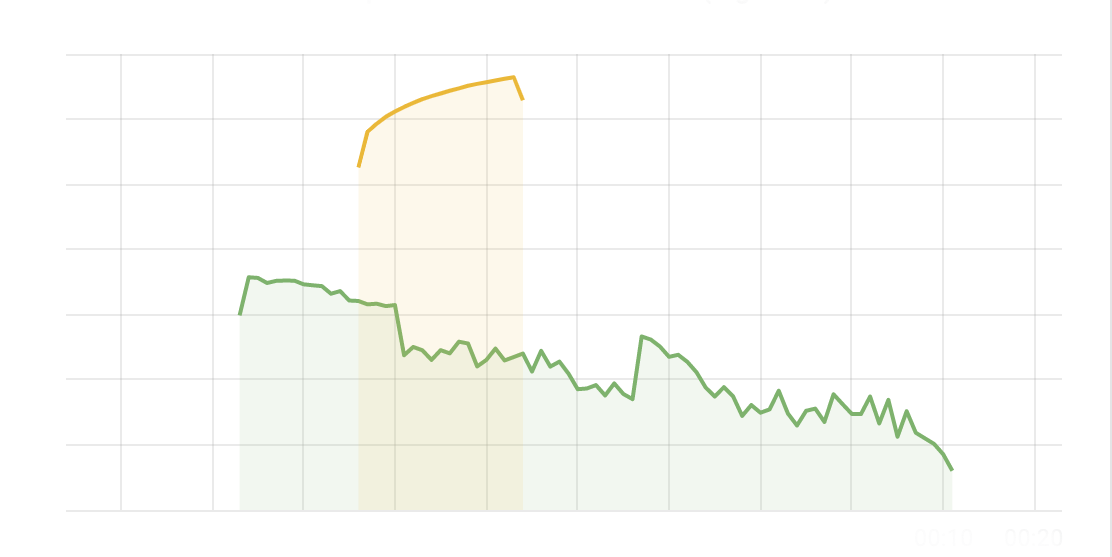
On January 24, 2022, as a result of an internal Cloudflare product migration, 24 hostnames (including www.cloudflare.com) that were actively proxied through the Cloudflare global network were mistakenly redirected to the wrong origin. During this incident, traffic destined for these hostnames was passed through to the clickfunnels.com origin and may have resulted in a clickfunnels.com page being displayed instead of the intended website. This was our doing and clickfunnels.com was unaware of our error until traffic started to reach their origin.
API calls or other expected responses to and from these hostnames may not have responded properly, or may have failed completely. For example, if you were making an API call to api.example.com, and api.example.com was an impacted hostname, you likely would not have received the response you would have expected.
Here is what happened:
At 2022-01-24 22:24 UTC we started a migration of hundreds of thousands of custom hostnames to the Cloudflare for SaaS product. Cloudflare for SaaS allows SaaS providers to manage their customers’ websites and SSL certificates at scale - more information is available here. This migration was intended to be completely seamless, with the outcome being enhanced Continue reading
Tech Bytes: Singtel And The Cloud-Ready Network (Sponsored)
Today on the Tech Bytes podcast we talk with sponsor Singtel, a global provider of network services. We dive into the services Singtel provides, including Internet, MPLS, IP transit 4G/5G, and why you might want to consider Singtel for cloud connectivity. Our guest is Mark Seabrook, Global Solutions Manager at Singtel.
The post Tech Bytes: Singtel And The Cloud-Ready Network (Sponsored) appeared first on Packet Pushers.
Tech Bytes: Singtel And The Cloud-Ready Network (Sponsored)
Today on the Tech Bytes podcast we talk with sponsor Singtel, a global provider of network services. We dive into the services Singtel provides, including Internet, MPLS, IP transit 4G/5G, and why you might want to consider Singtel for cloud connectivity. Our guest is Mark Seabrook, Global Solutions Manager at Singtel.Day Two Cloud 131: Monitoring The Cloud From The Cloud
Today's Day Two Cloud podcast delves into issues about monitoring all the things, including the notion of monitoring the cloud...from the cloud. Ned Bellavance and Ethan Banks discuss the pros and cons of DIY vs. using a service, differences between monitoring infrastructure stacks and applications, what to monitor and why, how to deal with all that data, the necessity of alerting, constructing meaningful dashboards, and more.
The post Day Two Cloud 131: Monitoring The Cloud From The Cloud appeared first on Packet Pushers.
Day Two Cloud 131: Monitoring The Cloud From The Cloud
Today's Day Two Cloud podcast delves into issues about monitoring all the things, including the notion of monitoring the cloud...from the cloud. Ned Bellavance and Ethan Banks discuss the pros and cons of DIY vs. using a service, differences between monitoring infrastructure stacks and applications, what to monitor and why, how to deal with all that data, the necessity of alerting, constructing meaningful dashboards, and more.NSX-T 3.2 Introduces Migration Coordinator’s User Defined Topology Mode
VMware NSX-T 3.2 is one of our largest releases — and it’s packed full of innovative features that address multi-cloud security, scale-out networking, and simplified operations. Check out the release blog for an overview of the new features introduced with this release.
Among those new features, let’s look at one of the highlights. With this release, Migration Coordinator now supports a groundbreaking feature addressing user-defined topology and enabling flexibility around supported topologies. In this blog post, we’ll look at the workflow for this new feature — starting with a high-level overview and then digging into the details of User Defined Topology. For more information on Migration Coordinator, check out the resource links at the end of this blog.
Migration Coordinator
Migration Coordinator is a tool that was introduced about 3 years ago with NSX-T 2.4. It enabled customers to migrate from NSX for vSphere to NSX-T Data Center. It’s a free and fully supported tool built into NSX-T Data Center. Migration Coordinator is flexible, with multiple options enabling multiple ways to migrate based on customer requirements.
Prior to NSX-T 3.2, Migration Coordinator offered two primary options:
- Migrate Everything: Migrate from edges to compute, to workloads in an automated fashion and with a workflow that resembles an in-place upgrade on existing Continue reading
The Normalization of Hybrid Work
After nearly two years of remote work, many organizations are ready to commit to a hybrid work model, where office workers spend time working from the office and home. What can IT leaders do to prepare for this new way of working? In this article, Palo Alto Networks’ Kumar Ramachandran shares some of his top insights and predictions for 2022 and the transition to hybrid work.DPU-Based Smart Interfaces And The Future Of Network Functions And Security At The Edge
This article was originally posted on Packet Pushers Ignition on April 26, 2021. Data center virtualization exacerbated problems for network security designs that relied on a handful of appliance-based (whether physical or virtual) control points, which typically focused on external threats. With advanced persistent threats (APTs) that focus on compromising internal systems, security strategies must […]
The post DPU-Based Smart Interfaces And The Future Of Network Functions And Security At The Edge appeared first on Packet Pushers.
Landscape of API Traffic

In recent years we have witnessed an explosion of Internet-connected applications. Whether it is a new mobile app to find your soulmate, the latest wearable to monitor your vitals, or an industrial solution to detect corrosion, our life is becoming packed with connected systems.
How is the Internet changing because of this shift? This blog provides an overview of how Internet traffic is evolving as Application Programming Interfaces (APIs) have taken the centre stage among the communication technologies. With help from the Cloudflare Radar team, we have harnessed the data from our global network to provide this snapshot of global APIs in 2021.
The huge growth in API traffic comes at a time when Cloudflare has been introducing new technologies that protect applications from nascent threats and vulnerabilities. The release of API Shield with API Discovery, Schema Validation, mTLS and API Abuse Detection has provided customers with a set of tools designed to protect their applications and data based on how APIs work and their challenges.
We are also witnessing increased adoption of new protocols. Among encryption protocols, for example, TLS v1.3 has become the most used protocol for APIs on Cloudflare while, for transport protocols, we Continue reading
Three Dimensions of BGP Address Family Nerd Knobs
Got into an interesting BGP discussion a few days ago, resulting in a wild chase through recent SRv6 and BGP drafts and RFCs. You might find the results mildly interesting ;)
BGP has three dimensions of address family configurability:
- Transport sessions. Most vendors implement BGP over TCP over IPv4 and IPv6. I’m sure there’s someone out there running BGP over CLNS1, and there are already drafts proposing running BGP over QUIC2.
- Address families enabled on individual transport sessions, more precisely a combination of Address Family Identifier (AFI) and Subsequent Address Family Identifier.
- Next hops address family for enabled address families.
Three Dimensions of BGP Address Family Nerd Knobs
Got into an interesting BGP discussion a few days ago, resulting in a wild chase through recent SRv6 and BGP drafts and RFCs. You might find the results mildly interesting ;)
BGP has three dimensions of address family configurability:
- Transport sessions. Most vendors implement BGP over TCP over IPv4 and IPv6. I’m sure there’s someone out there running BGP over CLNS1, and there are already drafts proposing running BGP over QUIC2.
- Address families enabled on individual transport sessions, more precisely a combination of Address Family Identifier (AFI) and Subsequent Address Family Identifier.
- Next hops address family for enabled address families.