Google Slows Hiring, Data Center Spend Due to COVID-19
“We are reevaluating the pace of our investment plans for the remainder of 2020,” Alphabet and...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Coronavirus Stunts IoT Insurgence
The rapid reversal is significant because the convergence of 5G, networks especially suited for...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Telefónica’s Security Biz Taps Google Cloud’s Chronicle
The deal comes as Google Cloud makes an all-out push to support mobile network operators.
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Vast Data Grows War Chest With $100M Funding Round, $1.2B Valuation
“Vast Data now has a $140 million war chest that we will spend like camels, not like unicorns,”...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Cloudflare Workers Now Support COBOL

Recently, COBOL has been in the news as the State of New Jersey has asked for help with a COBOL-based system for unemployment claims. The system has come under heavy load because of the societal effects of the SARS-CoV-2 virus. This appears to have prompted IBM to offer free online COBOL training.

As old as COBOL is (60 years old this month), it is still heavily used in information management systems and pretty much anywhere there’s an IBM mainframe around. Three years ago Thomson Reuters reported that COBOL is used in 43% of banking systems, is behind 80% of in-person financial transactions and 95% of times an ATM card is used. They also reported 100s of billions of lines of running COBOL.
COBOL is often a source of amusement for programmers because it is seen as old, verbose, clunky, and difficult to maintain. And it’s often the case that people making the jokes have never actually written any COBOL. We plan to give them a chance: COBOL can now be used to write code for Cloudflare’s serverless platform Workers.
Here’s a simple “Hello, World!” program written in COBOL and accessible at https://hello-world.cobol.workers.dev/. It doesn’t do much--it Continue reading
Cisco to Offer Online Testing
Other vendors such as Juniper and AWS have already started doing it, now it’s Cisco’s turn to offer online testing. This is especially welcome in Covid times where it’s difficult to go visit an on-premises Pearson/Vue test center. Starting April 15, Cisco will offer remote testing and this means you can take your test any time, any day, around the year. Almost all of the written tests will be offered, including the DevNet ones! The CCDE is one of the excluded tests.
What is required to take the test online? There are some prerequisites:
- Quiet, private location
- Reliable device with a webcam
- Strong Internet connection
- OnVUE software
- Government-issued identification
Your test will be proctored by an online proctor. Before the test starts, you will need to show your room, that there are no books or notes, that you are alone in the room and that you can close the room etc. As well that you are not wearing a watch or have access to a mobile phone. You will also need to provide a valid ID before starting the test. If you break any rules, you will of course not receive a passing score. You can find more information in Susie Wee’s Continue reading
Growing Beyond Ansible host_vars and group_vars
One of the attendees of my Building Network Automation Solutions online course quickly realized a limitation of Ansible (by far the most popular network automation tool): it stores all the information in random text files. Here’s what he wrote:
I’ve been playing around with Ansible a lot, and I figure that keeping random YAML files lying around to store information about routers and switches is not very uh, scalable. What’s everyone’s favorite way to store all the things?
He’s definitely right (and we spent a whole session in the network automation course discussing that).
IPv6 Buzz 049: IPv6 and Renumbering
In this week's episode Ed, Scott, and Tom discuss one of IT networking's biggest challenges, IP renumbering, and how IPv6 impacts (and is impacted by) it. Anyone who's ever had to do a significant IPv4 renumbering project knows just how labor intensive and painful this process can be. Will it be easier with IPv6? If so, how and why?
The post IPv6 Buzz 049: IPv6 and Renumbering appeared first on Packet Pushers.
IPv6 Buzz 049: IPv6 and Renumbering
In this week's episode Ed, Scott, and Tom discuss one of IT networking's biggest challenges, IP renumbering, and how IPv6 impacts (and is impacted by) it. Anyone who's ever had to do a significant IPv4 renumbering project knows just how labor intensive and painful this process can be. Will it be easier with IPv6? If so, how and why?Cloudflare Dashboard and API Outage on April 15, 2020
Starting at 1531 UTC and lasting until 1952 UTC, the Cloudflare Dashboard and API were unavailable because of the disconnection of multiple, redundant fibre connections from one of our two core data centers.
This outage was not caused by a DDoS attack, or related to traffic increases caused by the COVID-19 crisis. Nor was it caused by any malfunction of software or hardware, or any misconfiguration.
What happened
As part of planned maintenance at one of our core data centers, we instructed technicians to remove all the equipment in one of our cabinets. That cabinet contained old inactive equipment we were going to retire and had no active traffic or data on any of the servers in the cabinet. The cabinet also contained a patch panel (switchboard of cables) providing all external connectivity to other Cloudflare data centers. Over the space of three minutes, the technician decommissioning our unused hardware also disconnected the cables in this patch panel.
This data center houses Cloudflare’s main control plane and database and as such, when we lost connectivity, the Dashboard and API became unavailable immediately. The Cloudflare network itself continued to operate normally and proxied customer websites and applications continued to operate. As Continue reading
Samsung Taps Xilinx for 5G Beamforming
Xilinx announced the Versal adaptive compute acceleration platform platform in September 2019 and...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Kernel of Truth season 3 episode 4: Production Ready Automation
Subscribe to Kernel of Truth on iTunes, Google Play, Spotify, Cast Box and Sticher!
Click here for our previous episode.
In this episode hosts Roopa Prabhu and Brian O’Sullivan chat with Justin Betz about production grade automation and CI/CD workflows for continuous maintenance and deployment of your “infrastructure as code.” They also discuss how like any other software code, code to manage and automate your infrastructure (IAC) has to be maintained, fixed, withstand hardware and software upgrades — so how do you do that? Finally, the group talks about Open Source production quality automation code. Enjoy!
Guest Bios
Roopa Prabhu: Roopa Prabhu is Chief Linux Architect at Cumulus Networks. At Cumulus she and her team work on all things kernel networking and Linux system infrastructure areas. Her primary focus areas in the Linux kernel are Linux bridge, Netlink, VxLAN, Lightweight tunnels. She is currently focused on building Linux kernel dataplane for E-VPN. She loves working at Cumulus and with the Linux kernel networking and debian communities. Her past experience includes Linux clusters, ethernet drivers and Linux KVM virtualization platforms. She has a BS and MS in Computer Science. You can find her on Twitter at @__roopa.
Daily Roundup: Awake Security Displaces Cisco
Awake Security displaced Cisco; Ericsson beat out 5G rivals; and Viptela CEO launched multi-cloud...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
How Secure SD-WAN is the Foundation for Retail SD-Branch
Retail SD-branch needs a secure connection to ensure that customer data is kept safe. Secure SD-WAN...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Nuage Tags Asavie for SD-WAN Extension
The deal will see Nuage pair its SD-WAN 2.0 offering with Asavie’s SD Edge platform announced...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Ericsson Beats Out 5G Rivals to Replace BT’s Huawei Gear
The U.K. government is requiring operators to limit the use of Huawei equipment in the core of 5G...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.
Pushing BGP Flowspec rules to multiple routers
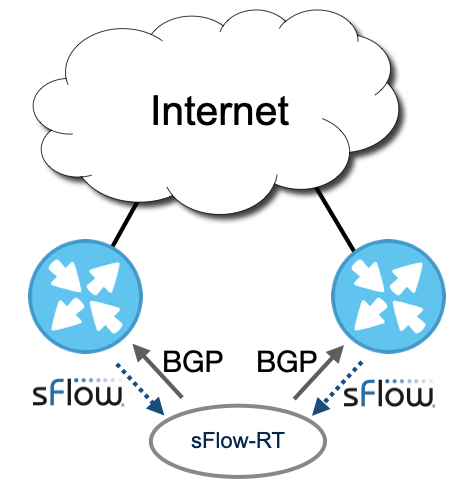
ddos_protect.router=10.0.0.96,10.0.0.97Configuring multiple BGP connections is simple, the ddos_protect.router configuration option has been extended to accept a comma separated list of IP addresses for the routers that will be connecting to the controller.
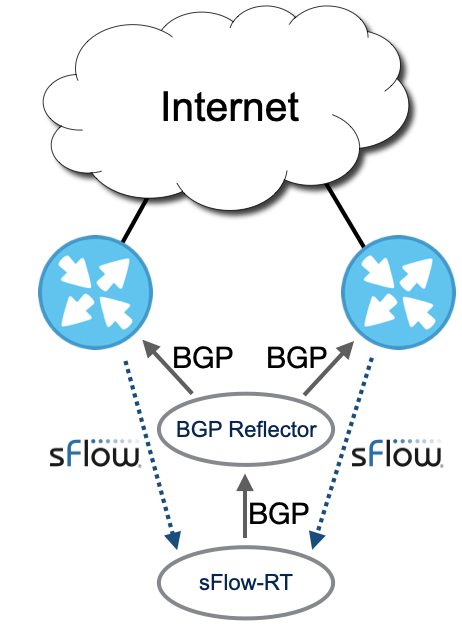
Support for multiple BGP connections in the DDoS Protect application reduces the complexity of simple deployments by removing the requirement for a reflector. Controls are pushed to all devices, but differentiated policies can still be implemented by configuring each device's response to controls.
Awake Security Scores $36M, Displaces Cisco, RSA, and Darktrace
Earlier this year Awake partnered with Google Cloud, which extended its network traffic analysis...
© SDxCentral, LLC. Use of this feed is limited to personal, non-commercial use and is governed by SDxCentral's Terms of Use (https://www.sdxcentral.com/legal/terms-of-service/). Publishing this feed for public or commercial use and/or misrepresentation by a third party is prohibited.