Log every request to corporate apps, no code changes required
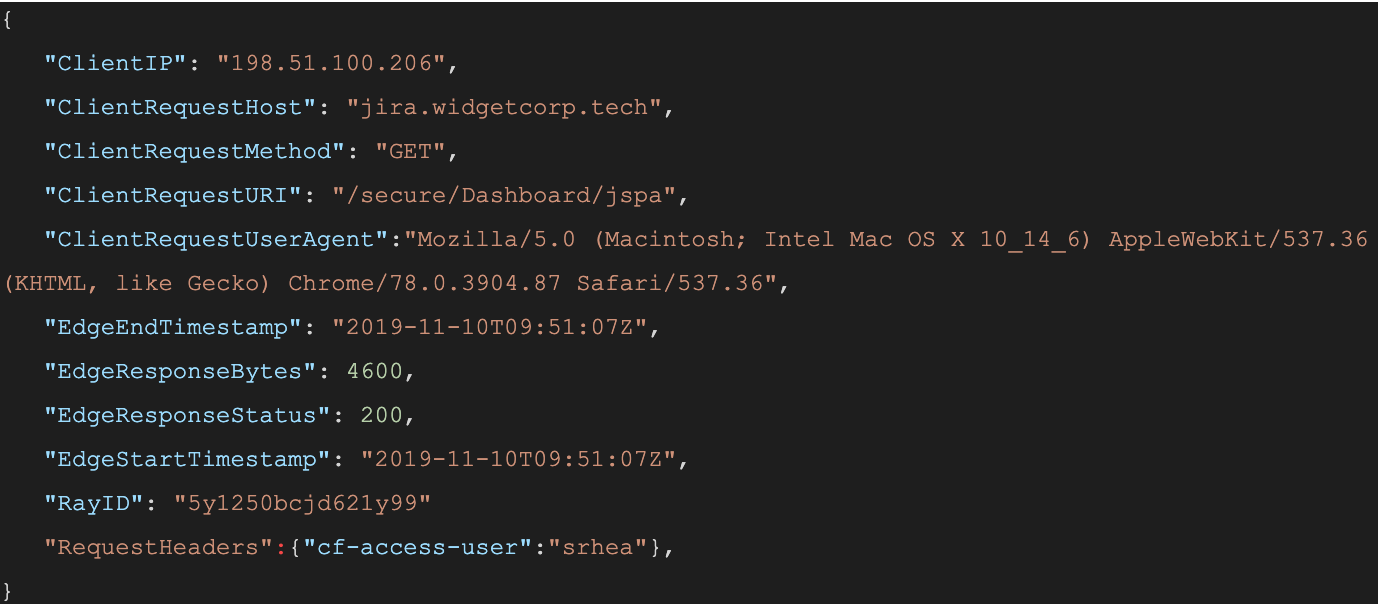
When a user connects to a corporate network through an enterprise VPN client, this is what the VPN appliance logs:

The administrator of that private network knows the user opened the door at 12:15:05, but, in most cases, has no visibility into what they did next. Once inside that private network, users can reach internal tools, sensitive data, and production environments. Preventing this requires complicated network segmentation, and often server-side application changes. Logging the steps that an individual takes inside that network is even more difficult.
Cloudflare Access does not improve VPN logging; it replaces this model. Cloudflare Access secures internal sites by evaluating every request, not just the initial login, for identity and permission. Instead of a private network, administrators deploy corporate applications behind Cloudflare using our authoritative DNS. Administrators can then integrate their team’s SSO and build user and group-specific rules to control who can reach applications behind the Access Gateway.
When a request is made to a site behind Access, Cloudflare prompts the visitor to login with an identity provider. Access then checks that user’s identity against the configured rules and, if permitted, allows the request to proceed. Access performs these checks on each request a user Continue reading


