HTTP Analytics for 6M requests per second using ClickHouse
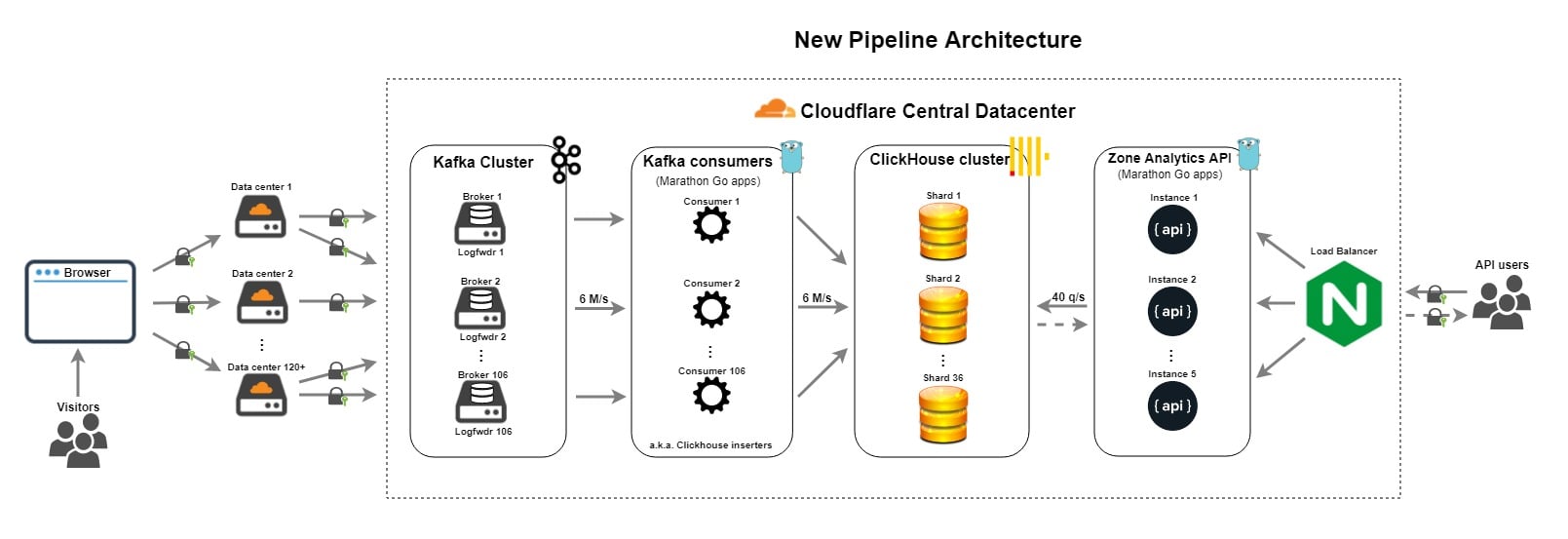
One of our large scale data infrastructure challenges here at Cloudflare is around providing HTTP traffic analytics to our customers. HTTP Analytics is available to all our customers via two options:
- Analytics tab in Cloudflare dashboard
- Zone Analytics API with 2 endpoints
- Dashboard endpoint
- Co-locations endpoint (Enterprise plan only)
In this blog post I'm going to talk about the exciting evolution of the Cloudflare analytics pipeline over the last year. I'll start with a description of the old pipeline and the challenges that we experienced with it. Then, I'll describe how we leveraged ClickHouse to form the basis of a new and improved pipeline. In the process, I'll share details about how we went about schema design and performance tuning for ClickHouse. Finally, I'll look forward to what the Data team is thinking of providing in the future.
Let's start with the old data pipeline.
Old data pipeline
The previous pipeline was built in 2014. It has been mentioned previously in Scaling out PostgreSQL for CloudFlare Analytics using CitusDB and More data, more data blog posts from the Data team.
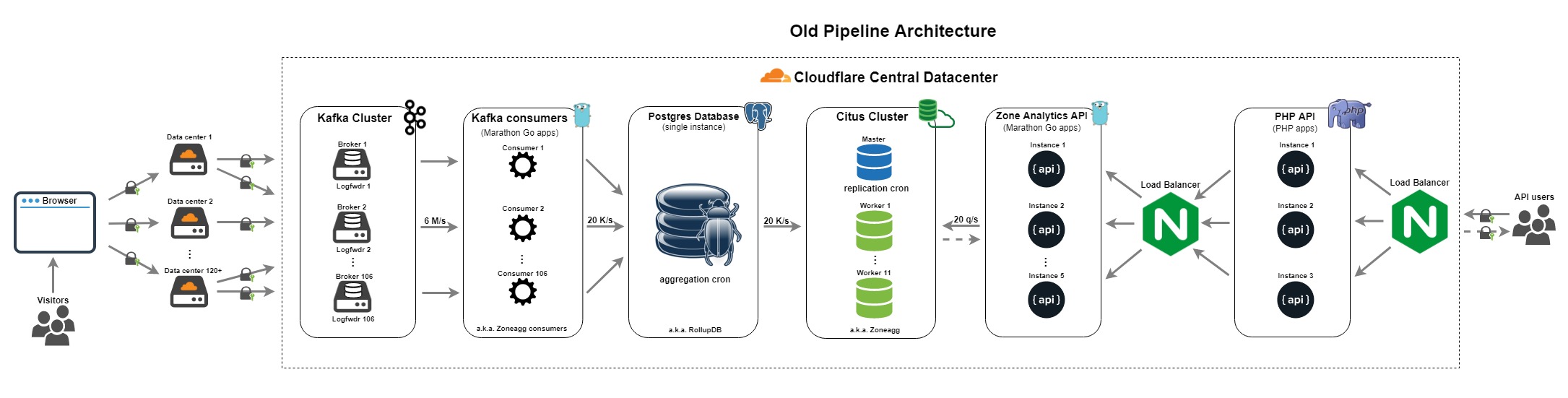
It had following components:
- Log forwarder - collected Cap'n Proto formatted logs from the edge, notably DNS and Nginx logs, Continue reading

 The project was the first adopted by CNCF.
The project was the first adopted by CNCF. AT&T's Chris Rice, SVP of Domain 2.0, praises the new chip.
AT&T's Chris Rice, SVP of Domain 2.0, praises the new chip. He'll report to VMware Founder and former CEO Diane Greene at Google Cloud.
He'll report to VMware Founder and former CEO Diane Greene at Google Cloud. Netsurion's SD-WAN is targeted to multi-tenant enterprises.
Netsurion's SD-WAN is targeted to multi-tenant enterprises.
 The new programmable chipset nears Shannon's limit in terms of performance.
The new programmable chipset nears Shannon's limit in terms of performance.