In this episode Tom and Scott explore Zero Trust Architecture (ZTA), where it aligns (and doesn't) with IPv6, and what the future might hold for both technologies.
We have always strived to make Cloudflare somewhere where our entire team feels safe and empowered to bring their whole selves to work. It’s the best way to enable the many incredible people we have working here to be able to do their best work. With that as context, we are proud to share that Cloudflare has been certified and recognized as one of the Top 100 Most Loved Workplaces in 2023 by Newsweek and the Best Practice Institute (BPI) for the second consecutive year.
Cloudflare’s ranking follows surveys of more than 2 million employees at companies with team sizes ranging from 50 to 10,000+, and includes US-based firms and international companies with a strong US presence. As part of the qualification for the certification, Cloudflare participated in a company-wide global employee survey — so this award isn’t a hypothetical, it’s driven by our employees’ sentiment and responses.
With this recognition, we wanted to reflect on what’s new, what’s remained the same, and what’s ahead for the team at Cloudflare. There are a few things that especially stand out:
The UK’s Competition and Markets Authority (CMA) is set to launch an investigation into the country’s cloud computing market, after a new report from the communications regulator uncovered a number of market features that it said could limit competition among providers.The move comes seven months after the communications regulator Ofcom first raised “significant concerns” about Amazon Web Services (AWS) and Microsoft, alleging that they were harming competition in cloud infrastructure services and abusing their market positions with practices that make interoperability difficult.To read this article in full, please click here
OARC held a 2-day meeting in September in Danang, Vietnam, with a
set of presentations on various DNS topics. Here’s some observations
that I picked up from the presentations that were made that meeting.
This post introduces Cisco's approach to Intent-based Networking (IBN) through their Centralized SDN Controller, DNA Center, rebranded as Catalyst Center. We focus on the network green field installation, showing workflows, configuration parameters, and relationships and dependencies between building blocks.
Figure 1-1 is divided into three main areas: a) Onboard and Provisioning, b) Network Hierarchy and Global Network Settings, c) and Configuration Templates and Site Profiles.
We start a green field network deployment by creating a Network Design. In this phase, we first build a Network Hierarchy for our sites. For example, a hierarchy can define Continent/Country/City/Building/Floor structure. Then, we configure global Network Settings. This phase includes both Network and Device Credentials configuration. AAA, DHCP, DNS serves, DNS name, and Time Zone, which are automatically inherited throughout the hierarchy, are part of the Network portion. Device Credentials, in turn, define CLI, SNMP read/write, HTTP(S) read/write username/password, and CLI enable password. The credentials are used later in the Discovery phase.
Next, we build a site and device type-specific configuration templates. As a first step, we create a Project, a folder for our templates. In Figure 1-1, we have a Composite template into which we attach two Regular templates. Regular templates include Continue reading
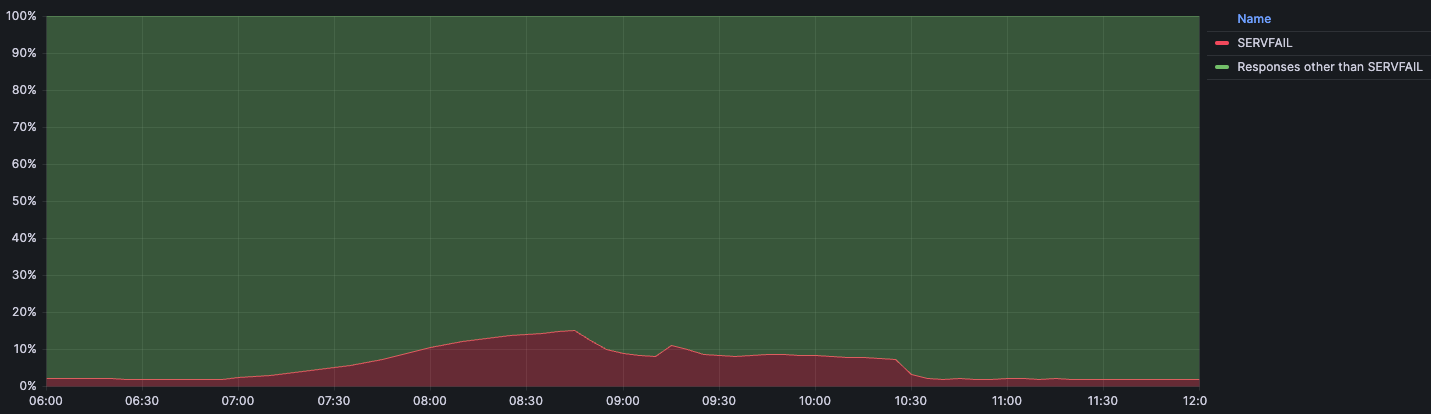
On 4 October 2023, Cloudflare experienced DNS resolution problems starting at 07:00 UTC and ending at 11:00 UTC. Some users of 1.1.1.1 or products like WARP, Zero Trust, or third party DNS resolvers which use 1.1.1.1 may have received SERVFAIL DNS responses to valid queries. We’re very sorry for this outage. This outage was an internal software error and not the result of an attack. In this blog, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
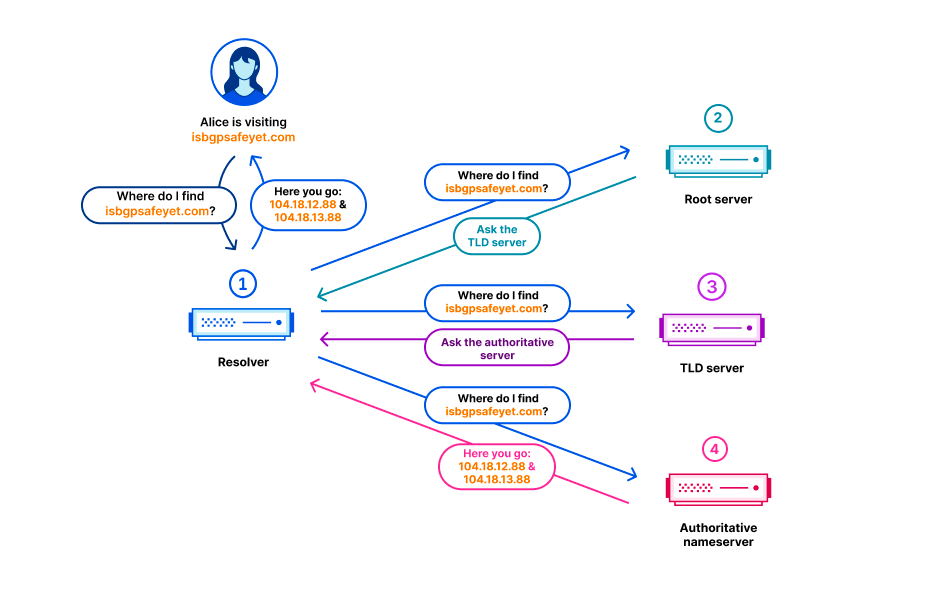
In the Domain Name System (DNS), every domain name exists within a DNS zone. The zone is a collection of domain names and host names that are controlled together. For example, Cloudflare is responsible for the domain name cloudflare.com, which we say is in the “cloudflare.com” zone. The .com top-level domain (TLD) is owned by a third party and is in the “com” zone. It gives directions on how to reach cloudflare.com. Above all of the TLDs is the root zone, which gives directions on how to reach TLDs. This means that the root zone is important Continue reading
Le 4 octobre 2023, Cloudflare a rencontré des problèmes de résolution DNS à partir de 7 h UTC, et ce jusqu'à 11 h UTC. Certains utilisateurs de 1.1.1.1 ou de produits tels que WARP, Zero Trust ou d'autres résolveurs DNS tiers utilisant 1.1.1.1 peuvent avoir reçu des réponses SERVFAIL DNS à leurs requêtes, pourtant valides. Nous sommes sincèrement désolés pour cette panne. Celle-ci était due à une erreur logicielle interne et n'était aucunement le résultat d'une attaque. Cet article de blog va nous permettre de discuter de la nature de cette défaillance, des raisons pour lesquelles elle s'est produite et des mesures que nous avons mises en œuvre pour nous assurer qu'une telle situation ne se reproduise jamais.
Contexte
Dans le Domain Name System (DNS, système de noms de domaine), chaque nom de domaine existe au sein d'une zone DNS. Cette zone constitue un ensemble de noms de domaine et de noms d'hôte, contrôlés conjointement. Pour prendre un exemple, Cloudflare est responsable du nom de domaine cloudflare.com, que nous disons se trouver dans la zone « cloudflare.com ». Le domaine de premier niveau (TLD, Top-Level Domain) « .com » est détenu par Continue reading
Am 4. Oktober 2023 traten bei Cloudflare Probleme bei der DNS-Auflösung auf, die um 07:00 UTC begannen und um 11:00 UTC endeten. Einige Nutzer von 1.1.1.1 oder Produkten wie WARP, Zero Trust oder DNS-Resolvern von Drittanbietern, die 1.1.1.1 verwenden, haben möglicherweise SERVFAIL DNS-Antworten auf gültige Anfragen erhalten. Wir möchten uns vielmals für diesen Ausfall entschuldigen. Dieser Ausfall war ein interner Softwarefehler und nicht das Ergebnis eines Angriffs. In diesem Blogartikel werden wir erläutern, was der Fehler war, warum er auftrat und was wir unternehmen, um sicherzustellen, dass sich so etwas nicht wiederholt.
Hintergrund
Im Domain Name System (DNS) existiert jeder Domain-Name innerhalb einer DNS-Zone. Die Zone ist eine Sammlung von Domain-Namen und Host-Namen, die gemeinsam kontrolliert werden. So ist Cloudflare beispielsweise für die Domain cloudflare.com verantwortlich, die sich in der Zone „cloudflare.com“ befindet. Die Top-Level-Domain (TLD) .com gehört einer dritten Partei und befindet sich in der Zone „com“. Sie gibt Auskunft darüber, wie cloudflare.com zu erreichen ist. Über allen TLDs befindet sich die Root-Zone, die Hinweise darauf gibt, wie die TLDs erreicht werden. Das bedeutet, dass die Root-Zone wichtig ist, um alle anderen Domain-Namen auflösen zu können. Wie andere wichtige Continue reading
El 4 de octubre de 2023, Cloudflare sufrió problemas en la resolución de DNS entre las 07:00 y las 11:00 UTC. Algunos usuarios de 1.1.1.1 o de productos como WARP, Zero Trust o de solucionadores DNS externos que utilicen 1.1.1.1 pueden haber recibido respuestas SERVFAIL DNS a consultas válidas. Lamentamos mucho esta interrupción. Fue debido a un error interno del software y no fue consecuencia de ningún ataque. En esta publicación del blog, hablaremos acerca de en qué consistió el fallo, por qué se produjo y qué estamos haciendo para garantizar que no se repita.
Antecedentes
En el sistema de nombres de dominio (DNS), cada nombre de dominio existe en una zona DNS, que está formada por un conjunto de nombres de dominio y nombres de servidor que se controlan juntos. Por ejemplo, Cloudflare es responsable del nombre de dominio cloudflare.com, que decimos que está en la zona "cloudflare.com". El dominio de nivel superior (TLD) .com es propiedad de un tercero y está en la zona "com". Proporciona indicaciones acerca de cómo llegar a cloudflare.com. Por encima de todos los TLD se encuentra la zona raíz, que ofrece indicaciones Continue reading
2023 年 10 月 4 日,Cloudflare 於世界標準時 7:00 開始至 11:00 結束期間遇到 DNS 解析問題。1.1.1.1 或 Warp 、 Zero Trust 等產品的一些使用者,或使用 1.1.1.1 的第三方 DNS 解析程式可能已經收到對有效查詢的 SERVFAIL DNS 回應。對於此次服務中斷,我們深感抱歉。此次服務中斷為內部軟體錯誤,而非攻擊造成的結果。在這篇部落格中,我們將討論失敗的內容、發生的原因,以及我們可以採取哪些措施來確保這種情況不再發生。
背景
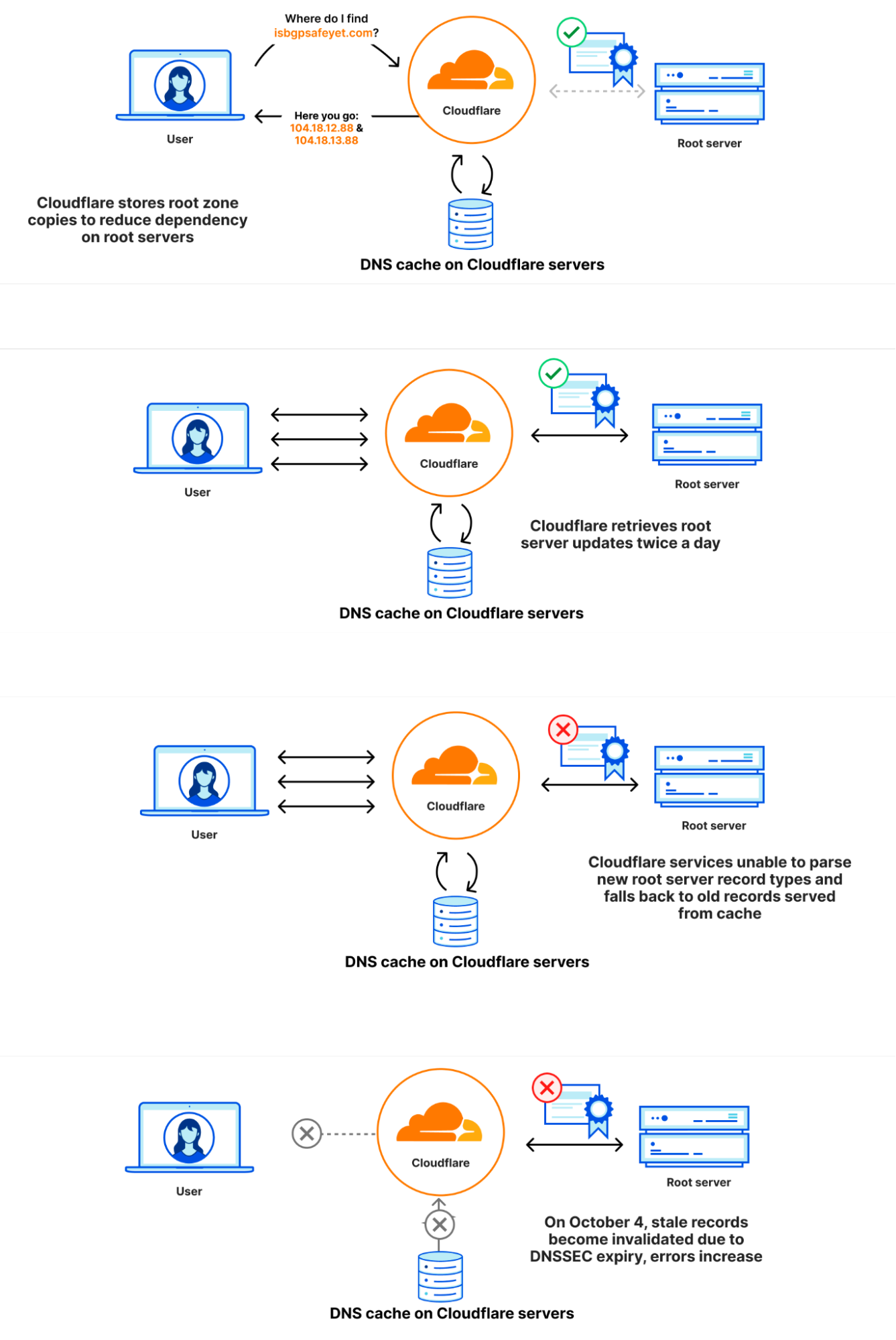
在 Domain Name System (DNS) 中,每一個網域名稱存在於 DNS 區域內。區域是在一起接受控制的網域名稱和主機名稱的集合。例如,Cloudflare 負責網域 cloudflare.com,我們稱之為「cloudflare.com」區域。頂級網域 (TLD) .com 由第三方擁有,位於「com」區域。它提供如何連線 cloudflare.com 的指示。所有 TLD 之上為根區域,提供如何連線 TLD 的指示。這意味著根區域對於解析所有其他網域名稱很重要。與 DNS 的其他重要部分一樣,根區域使用 DNSSEC 進行簽署,這也意味著根區域本身包含加密簽章。
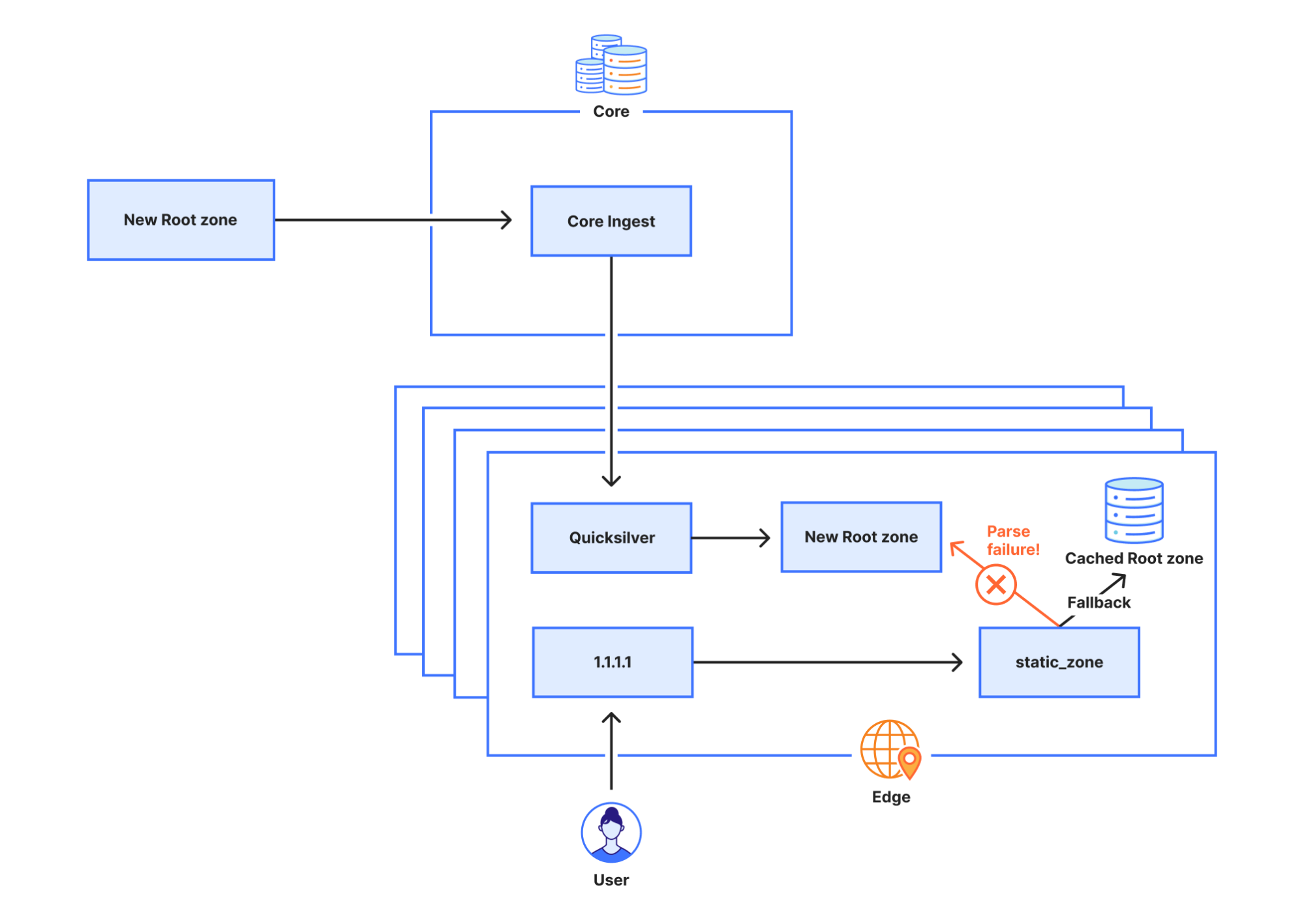
根區域發布於根伺服器上,但 DNS 營運商自動擷取並保留根區域副本的情況也很常見, 以便在無法連線根伺服器的情況下,根區域中的資訊仍然可供使用。Cloudflare 的遞迴 DNS 基礎架構會採用此方法,因為它還可加速解析程序。新版根區域通常一天發布兩次。1.1.1.1 具有稱為 static_zone 的 WebAssembly 應用程式,該應用程式執行於主 DNS 邏輯之上,當新版本可供使用時,即可提供這些新的版本。
根区在根服务器上发布,但 DNS 运营商通常也会自动检索并保留根区的副本,使得万一根服务器无法访问时,根区中的信息仍然可用。Cloudflare 的递归 DNS 基础设施也采用了这种方法,因为它还可以加快解析过程。根区的新版本通常每天发布两次。1.1.1.1 有一个名为 static_zone 的 WebAssembly 应用程序,它在主 DNS 逻辑的基础上运行,在新版本可用时为它们提供服务。
Just weeks after Cisco killed its Hyperflex platform and turned that business over to Nutanix, the vendors rolled out their first integrated hyperconverged infrastructure (HCI) package aimed at easing hybrid- and multi-cloud operations.HCI platforms combine storage, compute, networking and virtualization resources in a single system. The newly available Cisco Compute Hyperconverged with Nutanix combines Cisco’s SaaS-managed compute and networking gear with Nutanix’s Cloud Platform, which includes Nutanix Cloud Infrastructure, Nutanix Cloud Manager, Nutanix Unified Storage, and Nutanix Desktop Services. The system can be centrally managed via Cisco’s cloud-based Intersight infrastructure operations platform, and it supports Nutanix Acropolis Hypervisor (AHV) and VMware vSphere hypervisors.To read this article in full, please click here
Just weeks after Cisco killed its Hyperflex platform and turned that business over to Nutanix, the vendors rolled out their first integrated hyperconverged infrastructure (HCI) package aimed at easing hybrid- and multi-cloud operations.HCI platforms combine storage, compute, networking and virtualization resources in a single system. The newly available Cisco Compute Hyperconverged with Nutanix combines Cisco’s SaaS-managed compute and networking gear with Nutanix’s Cloud Platform, which includes Nutanix Cloud Infrastructure, Nutanix Cloud Manager, Nutanix Unified Storage, and Nutanix Desktop Services. The system can be centrally managed via Cisco’s cloud-based Intersight infrastructure operations platform, and it supports Nutanix Acropolis Hypervisor (AHV) and VMware vSphere hypervisors.To read this article in full, please click here
On 2023-10-04 at 13:00 UTC, Atlassian released details of the zero-day vulnerability described as “Privilege Escalation Vulnerability in Confluence Data Center and Server” (CVE-2023-22515), a zero-day vulnerability impacting Confluence Server and Data Center products.
Cloudflare was warned about the vulnerability before the advisory was published and worked with Atlassian to proactively apply protective WAF rules for all customers. All Cloudflare customers, including Free, received the protection enabled by default. On 2023-10-03 14:00 UTC Cloudflare WAF team released the following managed rules to protect against the first variant of the vulnerability observed in real traffic.
When CVE-2023-22515 is exploited, an attacker could access public Confluence Data Center and Server instances to create unauthorized Confluence administrator accounts to access the instance. According to the advisory the vulnerability is assessed by Atlassian as critical. At the moment of writing a CVSS score is not yet known. More information can be found in the security advisory, including what versions of Confluence Server are affected.
Welcome to Day Two Cloud. If you want your journey to infrastructure automation to be successful, you have to prepare for that journey. On today's show we talk about how to lay the groundwork for infrastructure automation or Infrastructure as Code (IaC). And this isn't just about tools and training (though we do also discuss these). There are organizational, team, and personal elements required to help people to incorporate automation into their daily work.
Welcome to Day Two Cloud. If you want your journey to infrastructure automation to be successful, you have to prepare for that journey. On today's show we talk about how to lay the groundwork for infrastructure automation or Infrastructure as Code (IaC). And this isn't just about tools and training (though we do also discuss these). There are organizational, team, and personal elements required to help people to incorporate automation into their daily work.
As National Cybersecurity Awareness Month kicks off, it's a good time to reflect on how secure the systems you manage are – whether they’re running Linux, Windows or some other OS. While Linux is considered by many to be more secure due to its open-source nature and because privileges are clearly defined, it still warrants security reviews, and this month's focus on cybersecurity awareness suggests that an annual review is more than just a good idea.The designation became official in 2004, when President George W. Bush and Congress declared October to be National Cybersecurity Awareness Month. Keep in mind that in 2004, security practice often involved little more than updating antivirus software. Today, cybersecurity practices are much more intense as the threats have grown to be far more significant and far more challenging.To read this article in full, please click here