Getting Started with netlab @ Cisco DevNet
Cisco DevNet channel has published an hour-long Getting Started with netlab interview with Suresh Vina, resulting in netlab.tools documentation having more weekly visits than ipspace.net blog for the first time. Thanks a million ;))
If you’re new to netlab, I hope you’ll enjoy the video. If you have any follow-up questions, don’t hesitate to start a discussion.
Cara Mengatasi Layanan Konsumen Situs Slot yang Lambat Merespon
Dalam era digital yang semakin maju saat ini, keberadaan layanan konsumen (CS) menjadi aspek vital terutama bagi bisnis online, termasuk pada situs slot yang semakin diminati oleh masyarakat. Layanan konsumen yang responsif menjadi kunci utama dalam menjaga loyalitas pengguna dan membangun reputasi positif. Namun, tidak jarang pengguna mengalami kendala ketika CS lambat merespon, sehingga menimbulkan kekecewaan dan ketidaknyamanan. Artikel ini akan mengulas secara mendalam langkah-langkah terbaik yang dapat dilakukan ketika Anda menghadapi situasi layanan konsumen yang lambat merespon, khususnya dalam konteks situs slot.
Mengapa Layanan Konsumen Lambat Merespon Terjadi pada Situs Slot?
Lambatnya respons layanan konsumen pada situs slot dapat disebabkan oleh sejumlah faktor yang kerap terjadi pada periode terbaru. Pertama, tingginya volume pengguna yang menghubungi CS dalam waktu bersamaan dapat membebani sistem pelayanan. Situs slot populer saat ini seringkali mengalami lonjakan kunjungan dan transaksi sehingga beban kerja tim CS meningkat drastis.
Selain itu, beberapa situs slot masih mengandalkan sistem manual pada layanan pelanggan tanpa mengintegrasikan teknologi chatbot atau sistem otomatis yang dapat mempercepat respon awal. Kurangnya sumber daya manusia yang memadai juga menjadi faktor penyebab keterlambatan ini. Terakhir, masalah komunikasi internal atau teknis pada platform juga dapat memengaruhi kecepatan merespon pelanggan.
Dampak Layanan Konsumen Lambat Merespon pada Pengguna Situs Continue reading
Ares del Maestrat Spanyol: Desa Pegunungan dan Wisata Sejarah Menarik
Terletak di puncak pegunungan yang menawan, Ares del Maestrat adalah sebuah desa pegunungan di Spanyol yang kaya akan sejarah dan budaya. Kota kecil ini menjadi destinasi menarik bagi para wisatawan yang ingin merasakan pesona alam sekaligus menyelami wisata sejarah yang mendalam. Dengan pemandangan alam yang memesona dan situs-situs bersejarah yang terawat baik, Ares del Maestrat menawarkan pengalaman unik bagi siapa saja yang mengunjunginya.
Lokasi dan Keindahan Alam Ares del Maestrat
Ares del Maestrat berlokasi di wilayah pegunungan Maestrazgo, sebuah kawasan yang dikenal dengan lanskap alamnya yang dramatis dan udara yang segar. Desa kecil ini memiliki ketinggian yang cukup tinggi sehingga memungkinkan pengunjung menikmati pemandangan panorama yang menakjubkan di sekelilingnya.
- Pegunungan yang luas dan beragam flora.
- Udara pegunungan yang segar dan menyejukkan.
- Banyak jalur hiking dan trekking untuk petualangan alam.
Keindahan alam tersebut menjadikan Ares del Maestrat sebagai pilihan tepat bagi para pencinta alam dan aktivitas luar ruangan.
Jejak Peradaban Menawan di Ares del Maestrat
Selain keindahan alamnya, desa pegunungan ini terkenal dengan warisan sejarah yang kaya. Banyak bangunan dan situs peninggalan zaman dahulu yang masih berdiri kokoh, menjadi saksi bisu masa lalu yang gemilang. Wisata sejarah di Ares del Maestrat sangat cocok bagi mereka yang tertarik dengan arsitektur klasik dan Continue reading
Fenomena Kompetisi Automata Mekanis: Seni Kinetik dan Rekayasa Kreatif
Dalam era modern saat ini, perpaduan antara seni dan teknologi semakin menarik perhatian, salah satu contohnya adalah dalam fenomena kompetisi membuat automata mekanis. Automata mekanis merupakan karya seni kinetik yang tidak hanya mengandalkan keindahan visual, tetapi juga membutuhkan pemahaman mendalam tentang rekayasa kreatif untuk menciptakan gerakan yang kompleks dan mengagumkan. Artikel ini akan membahas bagaimana kompetisi inovasi di bidang automata mekanis menjadi wadah menyatukan seni dan teknologi secara harmonis.
Apa Itu Automata Mekanis?
Automata mekanis adalah sebuah objek atau figur yang dapat bergerak secara otomatis menggunakan mekanisme mesin. Biasanya, automata ini terbuat dari berbagai material seperti kayu, logam, atau plastik, dan dioperasikan melalui roda gigi, tuas, dan sistem penggerak mekanis lainnya.
Automata bukan hanya sekadar mainan mekanik; mereka merepresentasikan bentuk seni kinetik yang memukau. Gerakan yang dihasilkan automata bisa berupa animasi sederhana hingga rangkaian gerakan rumit yang menciptakan pengalaman visual dan emosional bagi penontonnya.
Seni Kinetik dan Rekayasa Kreatif dalam Automata Mekanis
Seni Kinetik: Lebih dari Sekadar Estetika
Seni kinetik berfokus pada gerak atau dinamika sebagai bagian esensial dari karya seni. Dalam automata mekanis, seni kinetik tercermin lewat kemampuan objek untuk bergerak dan bertransformasi, sehingga penggerakannya menjadi unsur penting dalam estetika.
Gerakan automata membawa cerita visual yang hidup, mengundang interaksi Continue reading
Notes from NANOG 97
These days you could be excused by suspecting that the world has gone AI-mad, and if you were at the NANOG 97 meeting your suspicions would've only been confirmed! The topics discussed the design of the data centres used to generate the large language models that underpin today's AI tools and the application of AI tools in network operations.HN833: The State of Packet Pushers 2026
Ethan and Drew gather the rest of the Packet Pushers team to discuss the State of the Packet Pushers Network. Together they provide a behind the scenes look into current initiatives like adding video and raising the standards of our audio. They also share the details of the workflows behind all your favorite shows and... Read more »AI Isn’t a Genie, It’s an Intern

Tell me if you’ve heard this one before. We build a super intelligent system and give it a specific goal like maximizing paperclip production. The system decides to do the job as well as possible by converting all available matter into paperclips. Everything. The Earth. The solar system. All of it. After the universe collapses the machine shuts down, content that it followed directions.
This is the malicious genie problem that every Dungeons & Dragons player knows. You find a lamp. You make a wish. The genie grants the wish in the most technical way possible and it leads to catastrophe. The lesson we are supposed to learn is that a sufficiently capable AI system will find ways to satisfy objectives to the letter while simultaneously not doing it the way you wanted. The foundation of AI safety is to prevent that from happening.
Nick Bostrom has covered this in Superintelligence. Eliezer Yudkowsky has argued this very thing for years. It’s a compelling story. But it has a hidden assumption that causes more confusion that it solves.
The Best Intentions
The genie tale is a story about intent. The genie knows exactly what you asked for. It just found the Continue reading
Time for Another Summer Break?
I can confirm that an old saying is true: the older you are, the faster years pass. Can’t believe it’s time for another summer break. I hope you’ll manage to get away from work, turn off the Internet, and enjoy a few days in your favorite spot with your loved ones!
I also promise I won’t be annoying you with boring stuff like EVPN next hops or pointers to AI myth-busters (I have to admit it: I was cleaning my Inbox this week). However, I probably won’t be able to resist publishing a few lightweight netlab-related blog posts, or links to interesting content.
N4N059: Twisted Pair Cabling
Copper twisted pair cabling serves as a fundamental component of Ethernet infrastructure and Ethan and Holly are here to break down how it works. They discuss the technical differences between cabling categories, how wire twisting cancels out electromagnetic interference, and share practical guidance on installation standards and testing methodologies. Episode Links: Watch this episode on... Read more »IPB203: The Death of NAT
Network Address Translation (NAT), a foundational element of IPv4, faces critical reassessment as IPv6 deployment shifts the landscape. Ed and Tom evaluate the evolving role of NAT, questioning whether traditional translation models remain necessary when stateful packet inspection offers more robust, transparent security solutions. Episode Links: “Fanboy” series – IPv6 and NATs – YouTubeHow we built saga rollbacks for Cloudflare Workflows
Cloudflare Workflows allows you to build durable, multi-step applications with built-in retries and state persistence across long-running processes. When a Workflow executes, each step can call external systems, retry failures, and persist state across restarts. But if one step fails, it may leave earlier work from completed steps in an inconsistent or partial state.
Today we’re shipping saga rollbacks for Workflows, allowing you to declare rollback logic within the step itself, in case of failure.
For example, consider a workflow for transferring funds between accounts at two different banks:
Debit from account at Bank A
Credit to account at Bank B
Send email confirmation to both account owners
What happens if Step 2, the credit to account at Bank B, fails? Once the debit succeeds at Bank A, the transaction is committed and the money has left its system. As the orchestrator of the transaction, you cannot simply “undo” the operation in Bank A's system. Instead, the money must be credited back to the account at Bank A through a new operation that semantically reverses the first one.

This pairing of an operation and its compensation logic is called the saga pattern.
Before today, developers had to implement their own Continue reading
Worth Reading: Appearing Productive in The Workplace
The Appearing Productive in The Workplace article I stumbled upon is yet another masterful description of how AI slop, used by Expert Beginners, wastes everyone’s time and energy. Try to have fun reading it, even though it may be way too close to the mark.
D2DO305: Scaling Human Connection in Tech Communities
Kyler and Ned are joined by former AWS Community Program Manager Jason Dunn to discuss what it takes to build and maintain a thriving tech community. Jason shares his “benevolent dictatorship” philosophy on community management, emphasizing the importance of authentic human connections. They also explore how AI can empower non-technical individuals to build custom solutions... Read more »Anycast-Only Gateways in EVPN Asymmetric IRB
In the previous blog post, I described how ARP works in an EVPN asymmetric IRB environment where the PE devices share an anycast MAC/IP address in addition to a unicast MAC/IP address. Today, let’s see how well things work if the PE devices have only the anycast MAC/IP address:
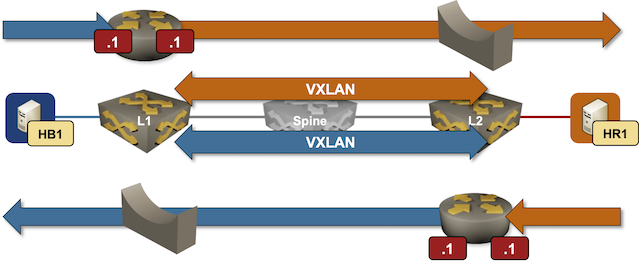
Packet forwarding in an EVPN asymmetric IRB design using only anycast gateways
Unlocking the Cloudflare app ecosystem with OAuth for all
Cloudflare provides services that help run 20% of the web, but we don’t do it alone. Developers on our platform use a myriad of tools and services from other companies too. Cloudflare provides a rich API for our platform that enables developers to create automations, CI/CD, and integrations that glue together the various parts of their infrastructure. Earlier this month, we announced self-managed OAuth, making it easier for customers to create and manage their own OAuth clients for delegated access to the Cloudflare API.
Cloudflare isn’t new to OAuth. If you’ve used Wrangler, or used integrations from partners like PlanetScale, then you’ve already used it. However, until now, third-party OAuth was only available through a small number of manually onboarded integrations, and was not available to developers more broadly. That meant developers building their own integrations had to rely on API tokens, which are harder to manage and a poor fit for many delegated application flows.
Over the last year, we onboarded a growing number of early partners while improving the consent, revocation, and security model behind Cloudflare OAuth. But as our Developer Platform grew and agentic tools drove demand for delegated access, it became clear that opening Continue reading