Use Python to translate TCP/UDP port numbers to names
This short post shows how you can use Python to convert TCP/UDP port number to port name and vice versa.
Most of us know names of common TCP and UDP ports like 22/ssh, 23/telnet, 80/http or 443/https. We learn these early in our networking careers and many of them are so common that even when woken up middle of the night you'd know 53 is domain aka dns!
But there are also many not-so commonly used ports that have been given names. These ones sometimes show up in firewall logs or are mentioned in literature. Some vendors also try to replace numeric value with a human readable name in the configs and outputs of different commands.
One way or the other, I'd be good to have an easy method of getting port number given its name, and on occasion we might want to get name of particular port number.
There are many ways one could achieve that. We might search web, drop into documentation, or even check /etc/services if we have access to Linux box.
I decided to check if we can do some programmatic translation with Python, seeing as sometimes we could have hundreds of entries to process and Continue reading
The Hedge 52: Tobi Metz and the Technologist Question
Tobi Metz asked What is a Technologists? in a recent blog post. Tobi joins Tom and Russ on this episode of the Hedge to expand on his answer, and get our thoughts on the question.
Day Two Cloud 066: Cloud Computing At The Edge(s)
Mark Thiele joins the Day Two Cloud podcast to school us on all things edge. He argues that edge is more than a buzzword, with a specific set of opportunities and challenges for IT operations and infrastructure.
The post Day Two Cloud 066: Cloud Computing At The Edge(s) appeared first on Packet Pushers.
Day Two Cloud 066: Cloud Computing At The Edge(s)
Mark Thiele joins the Day Two Cloud podcast to school us on all things edge. He argues that edge is more than a buzzword, with a specific set of opportunities and challenges for IT operations and infrastructure.What Will the Internet Look Like in 2030? New Grants Program for Researchers Studying the Future of the Internet

From the environment to the economy, the Internet is reshaping and disrupting several sectors of our society. What might future patterns of disruption look like? How will these changes affect all of us, particularly those on the margins of society? What new solutions can we generate today, to address the challenges of tomorrow?
At the Internet Society Foundation, we believe the answers to these questions and many others lies in research. That’s why we’re thrilled to announce a new grants program supporting researchers worldwide who are studying the future and sustainability of the Internet. Grants of up to US$200,000 are available for research lasting up to two years and focused in one of two categories:
- Greening the Internet: How the Internet affects and is affected by the environment
- The Internet Economy: How digital technologies are transforming our economic landscape
Established in 2019 to support the positive difference the Internet can make to people everywhere, the Internet Society Foundation awards grants to Internet Society Chapters/Special Interest Groups (SIGs) as well as nonprofit organizations and individuals dedicated to providing meaningful access to an open, globally-connected, secure, and trustworthy Internet for everyone.
Learn more about future calls for Continue reading
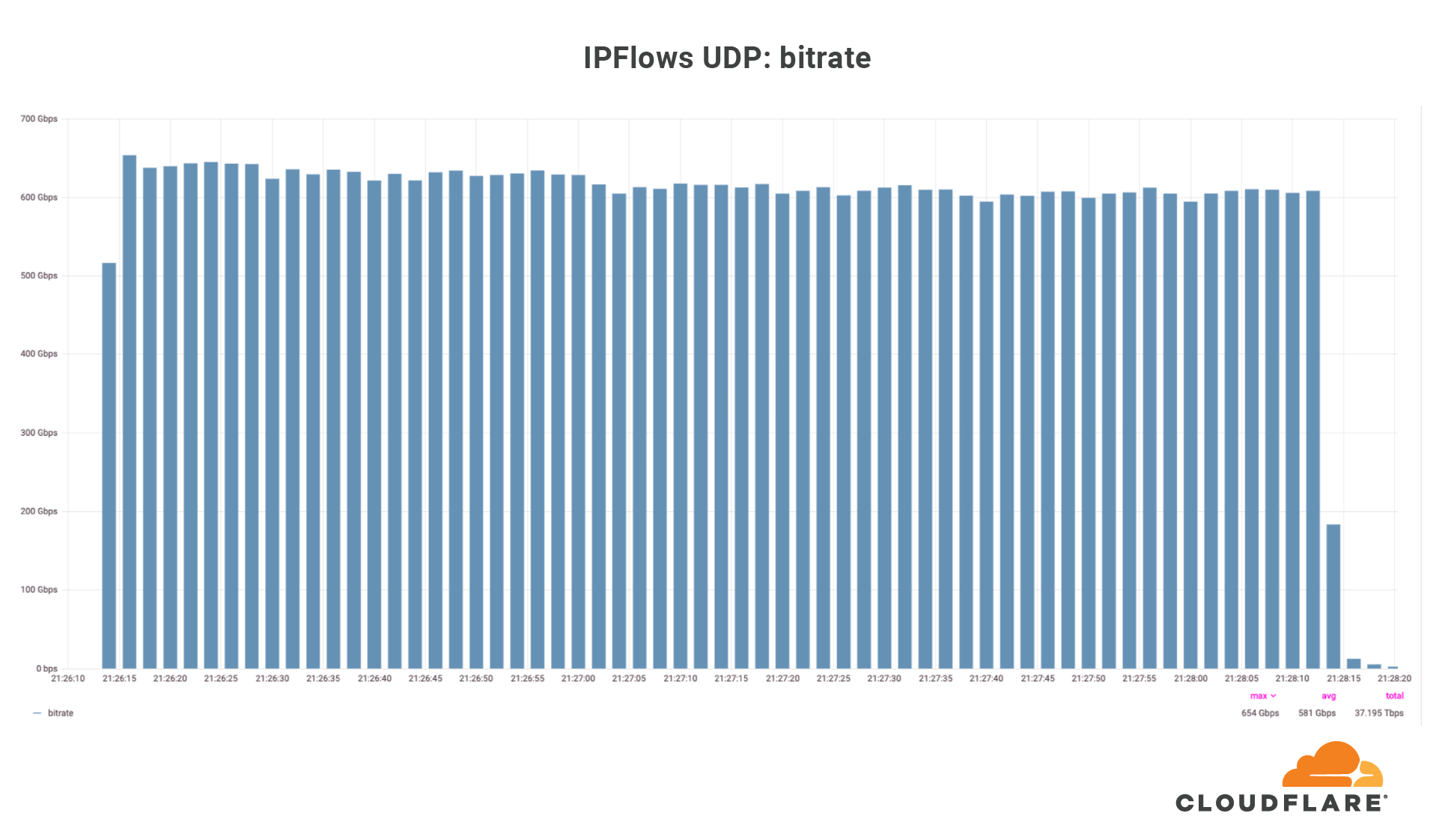
Moobot vs. Gatebot: Cloudflare Automatically Blocks Botnet DDoS Attack Topping At 654 Gbps
On July 3, Cloudflare’s global DDoS protection system, Gatebot, automatically detected and mitigated a UDP-based DDoS attack that peaked at 654 Gbps. The attack was part of a ten-day multi-vector DDoS campaign targeting a Magic Transit customer and was mitigated without any human intervention. The DDoS campaign is believed to have been generated by Moobot, a Mirai-based botnet. No downtime, service degradation, or false positives were reported by the customer.
Over those ten days, our systems automatically detected and mitigated over 5,000 DDoS attacks against this one customer, mainly UDP floods, SYN floods, ACK floods, and GRE floods. The largest DDoS attack was a UDP flood and lasted a mere 2 minutes. This attack targeted only one IP address but hit multiple ports. The attack originated from 18,705 unique IP addresses, each believed to be a Moobot-infected IoT device.
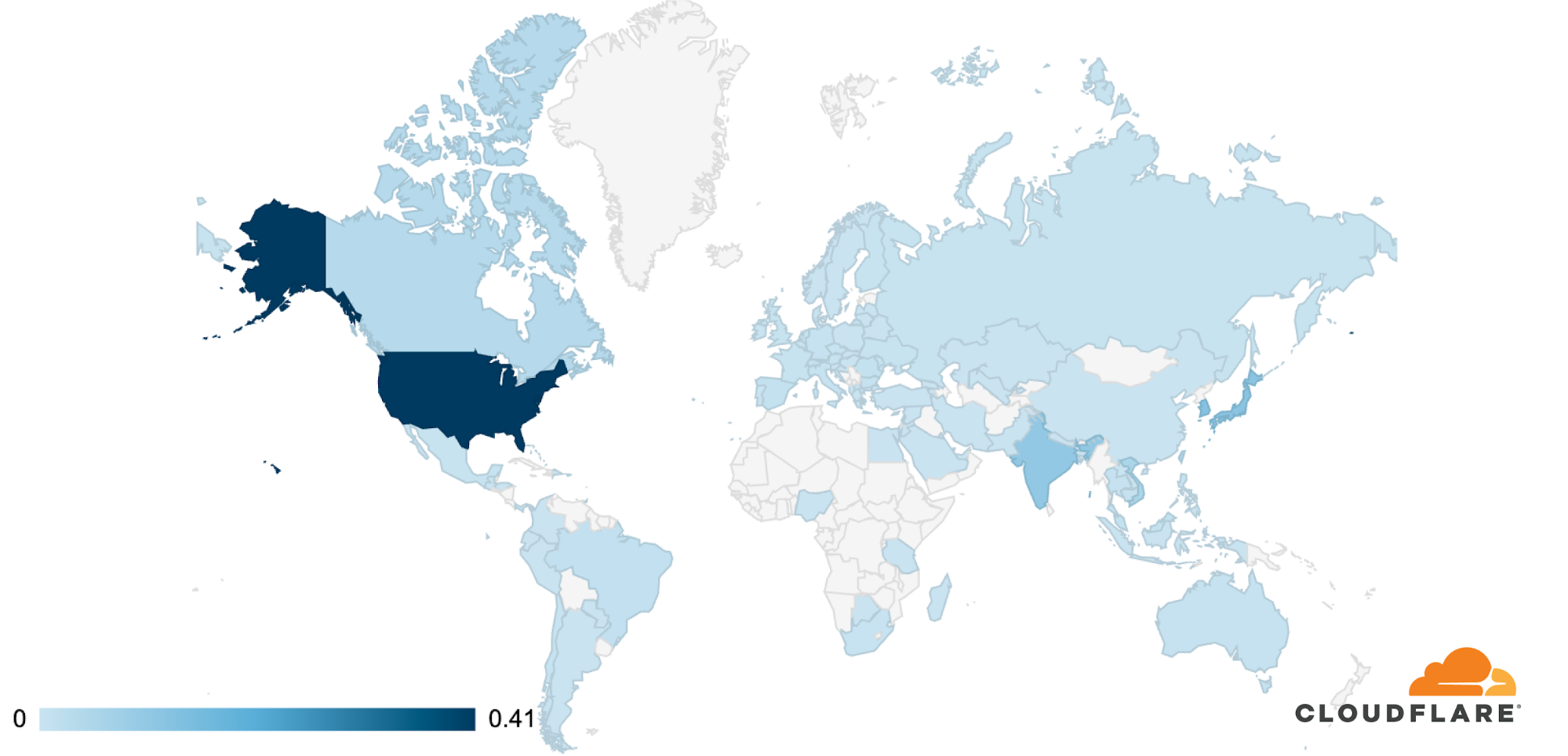
The attack was observed in Cloudflare’s data centers in 100 countries around the world. Approximately 89% of the attack traffic originated from just 10 countries with the US leading at 41%, followed by South Korea and Japan in second place (12% each), Continue reading
Restoring data to Netbox Docker
Having just shot myself in the foot by deleting docker and losing a container I had been working on, here is the command to restore data to netbox-docker’s Postgres database:
sudo docker exec -i netbox-docker_postgres_1 psql --username netbox netbox < /path/to/backup/file.sql
Phew…
Why Don’t We Have Dynamic Firewall Policies
One of the readers of the Considerations for Host-Based Firewalls blog post wrote this interesting comment:
Perhaps a paradigm shift is due for firewalls in general? I’m thinking quickly here but wondering if we perhaps just had a protocol by which a host could request upstream firewall(s) to open access inbound on their behalf dynamically, the hosts themselves would then automatically inform the security device what ports they need/want opened upstream.
Well, we have at least two protocols that could fit the bill: Universal Plug and Play and Port Control Protocol (RFC 6887).
Deloitte on Cloud, the Edge, and Enterprise Expectations
As technology matures to be cheaper, faster, and more powerful, it creates new possibilities with micro data centers and AI chips at the edge.A summary of High Speed Ethernet ASICs
There is a lot going on in the field of the highest speed network ASICs. These are focused on very high speed, less features, and lower buffers, driven by the hyperscalers and the Financial industry which desires the lowest latency switching. This is a rich area that I can’t cover...SD-LAN Helps Mitigate Smart Building Physical Cybersecurity Risks
The mitigation of smart building cyber security risk is shaping up to be one of the key driving factors that propels SD-LAN technologies into the mainstream.Member News: Kyrgyzstan Chapter Focuses on Online Resources for Schools

Library access: The Kyrgyzstan Chapter of the Internet Society has started work on version 2.0 of its ilimBox project, an online educational platform for teachers and students. The ilimBox device, now powered by the Raspberry Pi 4, will include new educational videos, audio, and text resources. IlimBox is a digital library for schools and public libraries, containing Wikipedia in Kyrgyz, Russian, and English, the Khan Academy electronic library in English, and thousands of video lessons, audio, and electronic books. All these digital training materials can be used offline, with users not needing immediate access to the Internet, although the library also connects to services through WiFi. As of last November, about 100 schools in Kyrgyzstan had installed ilimBox.
Building a better network: The Ghana Chapter has a post on efforts to improve the wireless network at Ho Technical University, and the author credited training from the Internet Society on community networks in helping him sort out problems with the network there. The campus network “had a lot of issues such rogue DHCP servers and IP address conflicts,” the author noted.
Algorithmic privacy: The Commission for the Protection of Privacy in Canada has given a grant to the Quebec Chapter Continue reading
The History of Comm Servers with Kevin Herbert
Communication Servers designed to support hundreds or thousands of users reached their peak capabilities just as dial-up service access began to recede in importance. In fact, many network engineers today have probably never managed a dial-up communications server, which were once used to connect everything from individual users to services like AOL and remote workers to entire sites (hence OSPF’s demand circuit capability). Kevin Herbert joins us to discuss the early work on communication servers, including some of the challenges of working with early networking hardware.