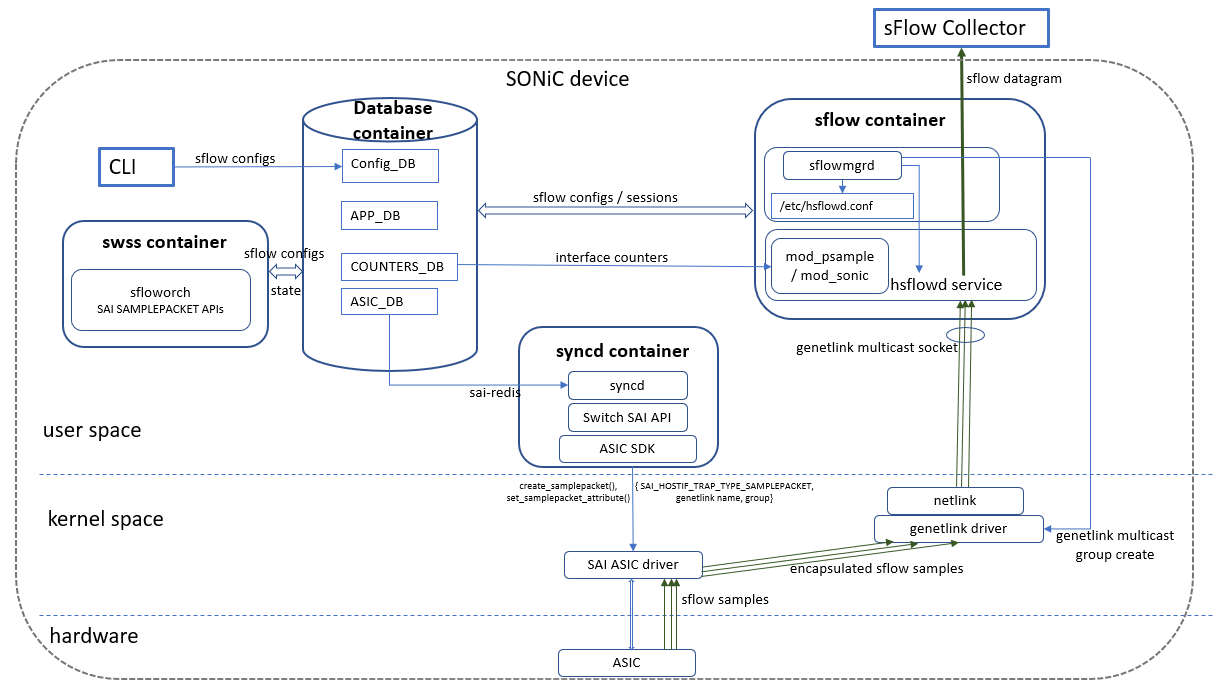
0
Cloudflare Access secures internal applications without the hassle, slowness or user headache of a corporate VPN. Access brings the experience we all cherish, of being able to access web sites anywhere, any time from any device, to the sometimes dreary world of corporate applications. Teams can integrate the single sign-on (SSO) option, like Okta or AzureAD, that they’ve chosen to use and in doing so make on-premise or self-managed cloud applications feel like SaaS apps.
However, teams consist of more than just the internal employees that share an identity provider. Organizations work with partners, freelancers, and contractors. Extending access to external users becomes a constant chore for IT and security departments and is a source of security problems.
Cloudflare Access removes that friction by simultaneously integrating with multiple identity providers, including popular services like Gmail or GitHub that do not require corporate subscriptions. External users login with these accounts and still benefit from the same ease-of-use available to internal employees. Meanwhile, administrators avoid the burden in legacy deployments that require onboarding and offboarding new accounts for each project.
We are excited to announce two new integrations that make it even easier for organizations to work securely with third parties. Starting Continue reading