Networking and Data Center Horrors That Scare IT Managers
While Halloween spooks people for one day, network and IT managers face a constant barrage of nightmares and horror stories year-round.Hedgehog, Kubernetes, And The Network Automation Conundrum
This post originally appeared in Human Infrastructure, the Packet Pushers’ weekly newsletter. See back issues and sign up here to get it. The networking startup Hedgehog recently emerged from stealth with a network fabric that brings together the open-source SONiC network OS (NOS) and the Kubernetes orchestration platform. The goal is to provide a distributed […]
The post Hedgehog, Kubernetes, And The Network Automation Conundrum appeared first on Packet Pushers.
Video: EVPN Multihoming Deep Dive
After starting the EVPN multihoming versus MLAG presentation (part of EVPN Deep Dive webinar) with the taxonomy of EVPN-based multihoming, Lukas Krattiger did a deep dive into its intricacies including:
- EVPN route types needed to support multihoming
- A typical sequence of EVPN updates during multihoming setup
- MAC multipathing, MAC aliasing, split horizon and mass withdrawals
- Designated forwarder election
You need Free ipSpace.net Subscription to watch the video. To watch the whole webinar, buy Standard or Expert ipSpace.net Subscription.
Video: EVPN Multihoming Deep Dive
After starting the EVPN multihoming versus MLAG presentation (part of EVPN Deep Dive webinar) with the taxonomy of EVPN-based multihoming, Lukas Krattiger did a deep dive into its intricacies including:
- EVPN route types needed to support multihoming
- A typical sequence of EVPN updates during multihoming setup
- MAC multipathing, MAC aliasing, split horizon and mass withdrawals
- Designated forwarder election
You need Free ipSpace.net Subscription to watch the video. To watch the whole webinar, buy Standard or Expert ipSpace.net Subscription.
Going Dark
There has been a concerted push to shroud many of the IETF's core protocols inside a claok of end-to-end encryption. This level of occlusion of the transactions that occur across the network from the network itself is not without its attendant risks, as Dr Paul Vixie outlined in a presentation at the recent NANOG 86 meeting.How the Brazilian Presidential elections affected Internet traffic

Brasil, sei lá
Ou o meu coração se engana
Ou uma terra igual não há
— From Tom Jobim’s song, Brasil Nativo

Brazil’s recent presidential election got significant attention from both global and national media outlets, not only because of the size of the country, but also because of premature allegations of electoral fraud. The first round of the Brazilian 2022 general election was held on October 2, and the runoff was held on Sunday, October 30. With 124 million votes counted, former president Lula da Silva (2003-2010) won with 50.9% of the votes, beating incumbent Jair Bolsonaro, who had 49.1% of the votes.
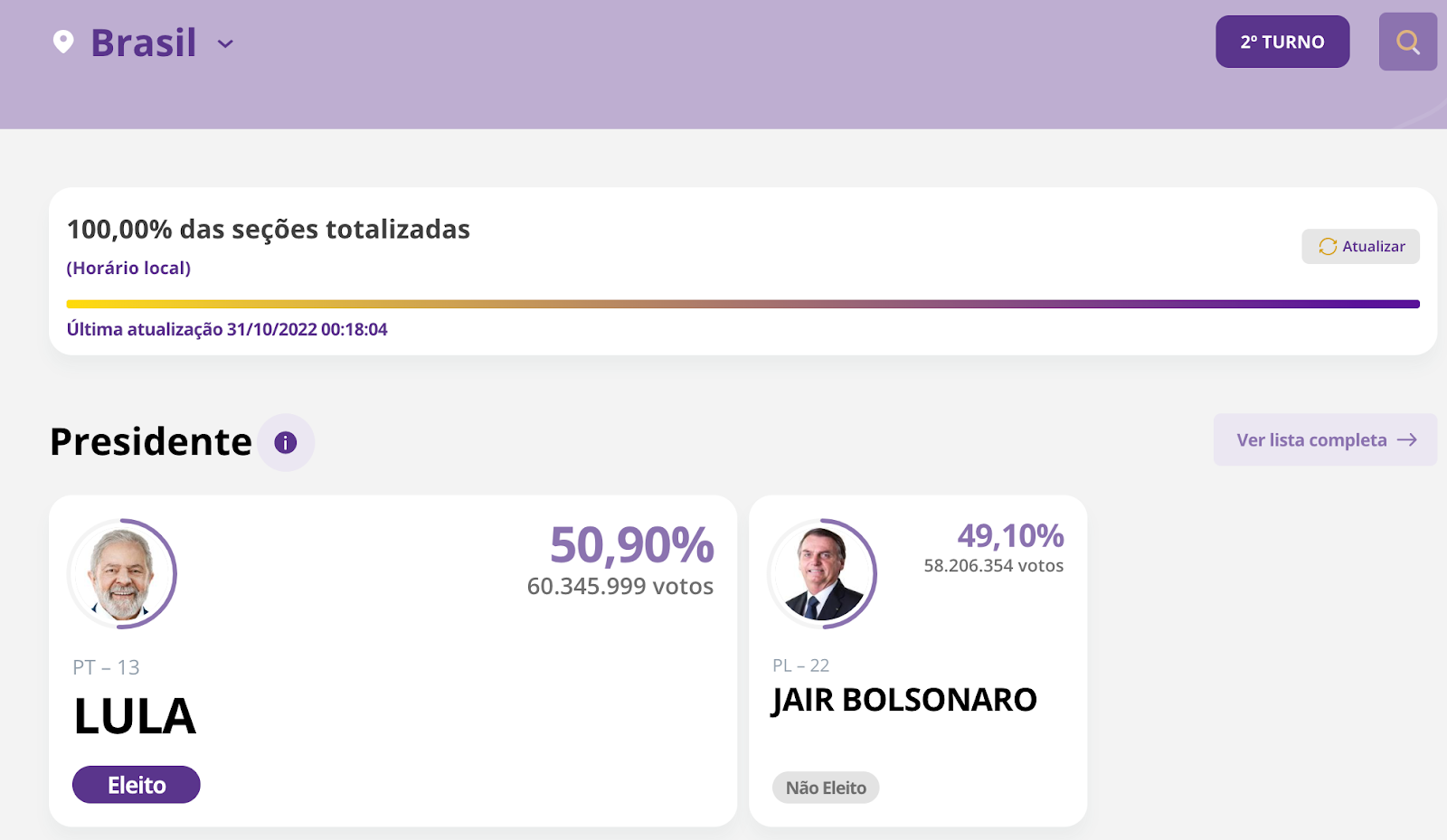
Using Cloudflare’s data, we can explore the impact that this election had on Internet traffic patterns in Brazil, as well as interest in content from election-related websites, news organizations, social media platforms, and video platforms.
Here are a few highlights: while the runoff generated much more interest to election related websites (we actually have a view to DNS queries, a proxy to websites), the first round showed bigger increases in traffic Continue reading
IPv6 Buzz 113: We Have DAD Issues (Duplicate Address Detection)
In this episode of IPv6 Buzz, Ed, Scott, and Tom talk about our DAD issues — well, our IPv6 Duplicate Address Detection (DAD) issues anyway. DAD is a feature of IPv6 that looks for duplicate IP addresses among hosts on the same segment. We discuss how it works and operational considerations.
The post IPv6 Buzz 113: We Have DAD Issues (Duplicate Address Detection) appeared first on Packet Pushers.
IPv6 Buzz 113: We Have DAD Issues (Duplicate Address Detection)
In this episode of IPv6 Buzz, Ed, Scott, and Tom talk about our DAD issues — well, our IPv6 Duplicate Address Detection (DAD) issues anyway. DAD is a feature of IPv6 that looks for duplicate IP addresses among hosts on the same segment. We discuss how it works and operational considerations.CI-Based Cloud Network Automation

A pioneer in cloud networking for the last decade, Arista has become synonymous with elastic scaling and programmable provisioning through a modern data-driven software stack. Legacy networks with manual box-by-box configurations for production and testing have led to cumbersome and complex practices. Arista leads the industry in cloud automation built on an open foundation.
Rant: Cloudy Snowflakes
I could spend days writing riffs on some of the more creative (in whatever dimension) comments left on my blog post or LinkedIn1. Here’s one about uselessness of network automation in cloud infrastructure (take that, AWS!):
If the problem is well known you can apply rules to it (automation). The problem with networking is that it results in a huge number of cases that are not known in advance. And I don’t mean only the stuff you add/remove to fix operational problems. A friend in one of the biggest private clouds was saying that more than 50% of transport services are customized (a static route here, a PBR there etc) or require customization during their lifecycle (e.g. add/remove a knob). Telcos are “worse” and for good reasons.
Yeah, I’ve seen such environments. I had discussions with a wide plethora of people building private and public (telco) clouds, and summarized the few things I learned (not many of them good) in Address the Business Challenges First part of the Business Aspects of Networking Technologies webinar.
Rant: Cloudy Snowflakes
I could spend days writing riffs on some of the more creative (in whatever dimension) comments left on my blog post or LinkedIn1. Here’s one about uselessness of network automation in cloud infrastructure (take that, AWS!):
If the problem is well known you can apply rules to it (automation). The problem with networking is that it results in a huge number of cases that are not known in advance. And I don’t mean only the stuff you add/remove to fix operational problems. A friend in one of the biggest private clouds was saying that more than 50% of transport services are customized (a static route here, a PBR there etc) or require customization during their lifecycle (e.g. add/remove a knob). Telcos are “worse” and for good reasons.
Yeah, I’ve seen such environments. I had discussions with a wide plethora of people building private and public (telco) clouds, and summarized the few things I learned (not many of them good) in Address the Business Challenges First part of the Business Aspects of Networking Technologies webinar.
Will New CISA Guidelines Help Bolster Cyber Defenses?
The new CISA guidance aims to shake up the way devices are tracked, managed, and protected against unauthorized access and attacksMicroStack installation fails on Ubuntu 20.04
I needed an instance of Openstack in my home lab for some tests and the first attempt was to deploy it with DevStack all-in-one. Is one of the most common methods out there. However it kept on failing (still need to find out why), so I turned to MicroStack. MicroStack describe itself as the most … Continue reading MicroStack installation fails on Ubuntu 20.04Hedge 153: Security Perceptions and Multicloud Roundtable
Tom, Eyvonne, and Russ hang out at the hedge on this episode. The topics of discussion include our perception of security—does the way IT professionals treat security and privacy helpful for those who aren’t involved in the IT world? Do we discourage users from taking security seriously by making it so complex and hard to use? Our second topic is whether multicloud is being oversold for the average network operator.